- 公開日
- 最終更新日
【Strands Agents】ブログレビューエージェントを作った際の学び
この記事を共有する

目次
はじめに
皆さんこんにちは!パーソル&サーバーワークスの小泉です。
今回は、Strands Agentを活用して社内ブログのレビュー業務を効率化し、レビュー負荷の軽減を目指しました。
しかし、思うようにいかなかったので、失敗した内容や得られた知見や学びについて共有します。
なぜブログレビューエージェントを作成したのか
前提として、弊社ではブログを執筆したら社内でダブルチェックを行い、一般公開しています。
このレビュー作業には以下のような課題がありました。
- ダブルチェック者が固定される
- レビュー者によって品質にばらつきがある
これらの課題を解決し、レビューの効率化と品質の担保を実現するため、ブログレビューエージェントを作成することにしました。
構成図
Strands Agentを用いて、以下の構成でレビューを実施する構成にしました。
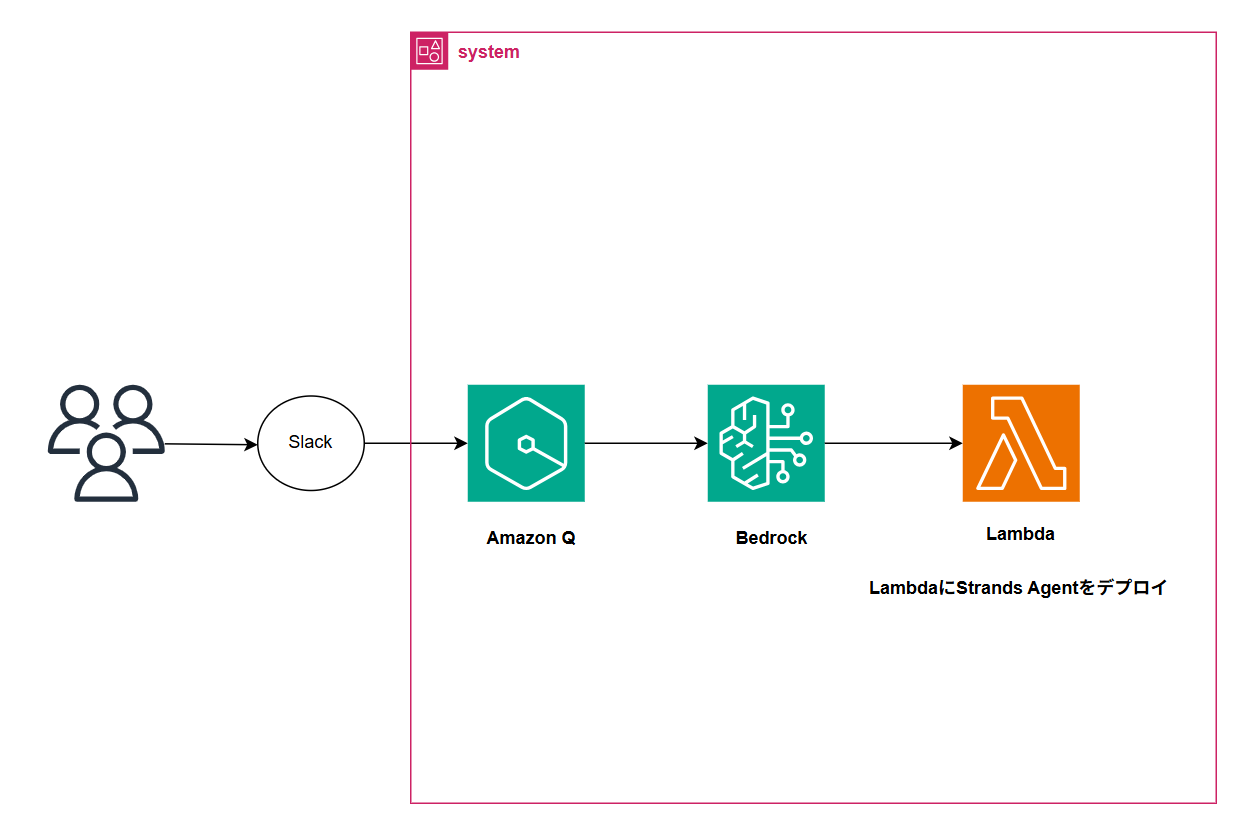
AIワークフロー
Strands Agentでは以下のようなワークフローにしました。
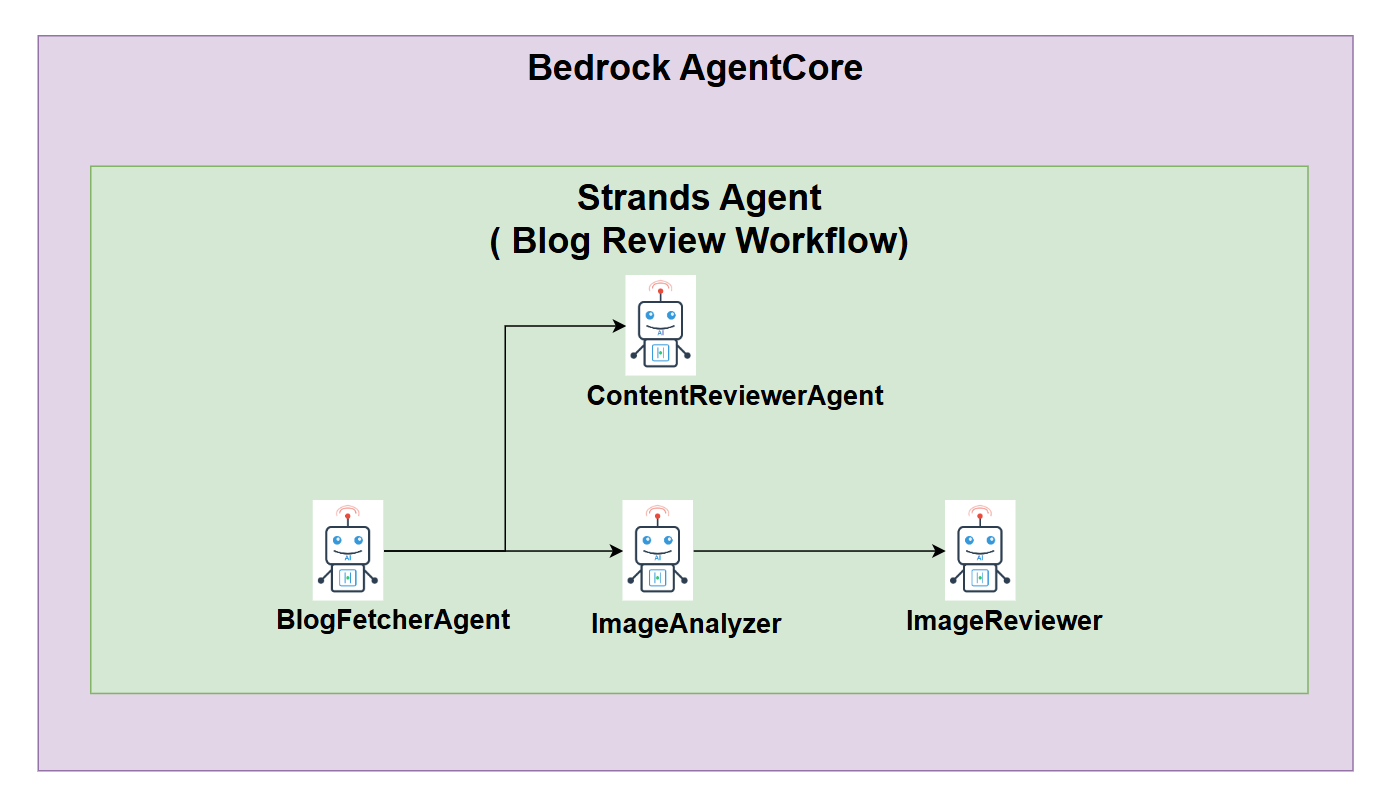
PJ構成
blog-agent/ ├── agent_blog_fetcher.py # ブログURLからコンテンツを取得 ├── agent_content_reviewer.py # ブログ内容をレビュー ├── agent_image_analyzer.py # ブログ記事内の画像を取得・分析 ├── agent_image_reviewer.py # 画像から抽出されたテキストをレビュー ├── blog_review_workflow.py # ブログレビューワークフロー ├── config.py # システム設定ファイル ├── Dockerfile ├── lambda_function.py └── requirements.txt
処理概要
- Slackからユーザーがブログ記事のURLを送信
- Bedrock AgentがURLを受け取り、Lambda関数を経由してBlogReviewWorkflowを実行
- BlogFetcherAgentが記事の内容を取得・解析
- 並列処理で以下を同時実行:
- 4-1. ContentReviewerAgent: 記事のテキスト内容をレビュー
- 4-2. ImageAnalyzerAgent: 記事内の画像を抽出・分析
- 4-3. ImageReviewerAgent: 画像内のテキストをレビュー
- Bedrock Agentが統合レビュー結果を受け取り、最終レポートをSlackに通知
当初の実装と課題
当初の実装では様々な課題がありました。特に大きかったのは以下の3つです。
1.ブログレビューエージェントの立ち位置
当初の案
ブログレビューエージェント内で全てのレビュー処理を完結させる。
課題
- 確認観点が多く、完全自動化は困難
- 最終的な責任の所在が不明確
最終的な運用フロー
1. 執筆者がエージェントにレビューを依頼
2. エージェントが自動レビューを実施し、一定の品質を担保
3. 品質が向上した状態でダブルチェック者(人間)が最終確認
効果
ダブルチェック者の負担を軽減しつつ、人間による最終確認で責任の所在を明確化できました。
2.どのようにブログ記事を取得するか
当初の案
ブログシステムのAPIを使用して記事を取得する。
課題
社内セキュリティの観点から難色を示された。
最終的な解決策
ブログのプレビュー機能を活用しました。
(ブログシステムに一時的なプレビュー画面を生成する機能があったため、これを利用して記事を取得する方式を採用しました)
3.レビュー範囲の指定
当初の案
取得した情報(テキストと画像)を全てレビュー対象とする。
- テキスト: レビュー観点に基づいてチェック
- 画像: Amazon Rekognition APIのOCR機能を用いて、画像内に機密情報(AWSアカウントIDなど)が含まれていないか判別
課題
取得した情報にレビュー不要なデータが含まれていた。
- サムネイル画像
- 関連記事の情報など
解決策
取得した情報からレビュー対象のみを抽出するフィルタリング処理を追加しました。
テスト運用で得られたフィードバックと改善
社内のエンジニアにテスト利用してもらい、以下のようなフィードバックを得ました。
- 「記事URLを入れたけど、Timeout Errorになる」
- 「レビュー結果が安定しない」
これらの問題に対して、以下の改善を行いました。
改善1: タイムアウトの解決
問題
多数の画像を含む記事の場合、処理が完了する前にタイムアウトが発生する。
原因
ImageAnalyzerAgentが画像を1枚ずつ順次処理していたため、画像数に比例して処理時間が増加していた。
対応
ImageAnalyzerAgentの処理を並列化し、複数の画像を同時に処理できるように改善しました。
改善2: レビュー精度の向上
当初の設計
以下のフローで実装していました。
- Slackからユーザーがブログ記事のURLを送信
- Bedrock AgentがURLを受け取り、Lambda関数を経由してBlogReviewWorkflowを実行
- BlogFetcherAgentが記事の内容を取得・解析
- 並列処理で各専門Agentがレビュー実施
- 統合レビューAgentが各レビュー結果を統合し、再度レビューを実施
- Bedrock Agentが統合レビュー結果を受け取り、最終レポートをSlackに通知
問題点
- 統合レビューAgentとBedrock Agentで二重にレビューが実施され、冗長な処理になっていた
- レビューの精度が一貫せず、品質にばらつきが生じた
対応
統合レビューAgentを削除し、各専門Agentのレビュー結果を直接Bedrock Agentに集約する構成に変更しました。
実行結果
改善後は完全ではないですが、前より安定してレビューが実行できるようになりました。
テスト運用の際の苦労
テスト運用を進める中で、技術的にも運用面でも多くの課題に直面しました。
まず、社内ユーザーからフィードバックをもらった後に、「どこを、どのように改善すべきかを切り分ける作業」が想像以上に大変でした。
具体的には、Bedrock Agentのアクショングループで実行されるLambdaのログをCloudWatch上で一つずつ確認しながら、どのAgentの出力が原因になっているのかなど考えながらを改善していました。
また、フィードバックを多くもらえるのは非常にありがたい一方で、「こんなにも改善ポイントがあるのか」と気付かされる場面も多く、実際に顧客向けにAI Agentを提供する際にはハードルが高いということを強く実感しました。
最後に、もう一つ大きな課題として、エージェントの評価の難しさがありました。
このエージェントが「どれくらい良いのか」を定量的に判断することが難しく、最終的に「どこを完成とみなすのか」という点にも悩みが残りました。
しかし、その点については、最近登場したAgentCore Evaluationsを用いた評価や、AgentCore Observabilityを活用することで、開発・運用時の負荷を下げられるのではないかと考えています。
まとめ
今回の取り組みを振り返ると、そもそものアーキテクチャ設計が最適ではなかったと感じています。
この構成を採用した理由としては、SlackからBedrock Agentを呼び出す方法を以下の記事で実施したことがあるので、その流れをそのまま踏襲してしまった、という背景がありました。
結果として、運用や改善面で課題が残る構成になってしまいました。
もし最初からBedrock AgentCoreにデプロイし、ObservabilityやEvaluate(作り始めた時にはなかった機能だが、)といった機能を前提に設計していれば、よりシンプルで改善しやすい構成にできたのではないかと感じています。
テスト運用中に感じていた「原因の特定がつらい」「どこを直せば良いかわからない」という苦しさは、まさにAgentCore EvaluationsやAgentCore Observabilityがリリースされた背景なのではないかと、テスト運用を実施して思いました。
今後は、社内エンジニアからのフィードバックを継続的に取り入れながら、アーキテクチャの見直しも含めて、より実運用に耐えうるブログレビューエージェントへ改善を重ねていきたいと思います。
この記事は私が書きました
小泉 和貴
記事一覧全国を旅行することを目標に、仕事を頑張っています。
