- 公開日
- 最終更新日
ChatGPTがオフラインで動く?!IT初心者がローカルLLMに挑戦してみた話
この記事を共有する

目次
はじめに
「AIって、企業が提供するサービスを使うもの」――そんな認識で、日々ChatGPTと仕事をしていた私。
まさか、自分で"作る側"にまわる日が来るなんて、思ってもみませんでした。
ある日、目に飛び込んできた「gpt-oss」というOSSプロジェクト。
なんと、GPTモデルをローカル環境で動かせるというじゃないですか!
しかも、オフラインで動作して、出力トーンまで調整できる。
「えっ、自分好みのAIが作れるの?!」と、広報のはずなのに技術チャレンジ魂に火がついてしまいました。
このブログでは、そんな私がAIと二人三脚でローカルLLMを構築してみた奮闘記をお届けします。
失敗もたくさんありましたが、同僚の力も借りながら、少しずつ前に進んでいます。
自己紹介とAIへの興味
はじめまして。パーソル&サーバーワークスで広報を担当している、大野です。
社内外の広報活動やマーケティング施策の検討、イベント企画、ブログのアイキャッチ作成、SNS運用などを担当しています。
実は、ずっとエンジニアに憧れを持っていて、Rubyを勉強したこともあります。
(作りたいものが浮かばず、そこで止まってしまいましたが...笑)
今は特にAIに強い興味があり、ChatGPTをはじめとする生成AIとの対話がとても楽しくて、
ヒューマノイドロボットを含めた未来の共創にもワクワクしています。
ChatGPTを本格的に使い始めたのは今年の4月。
広報に異動したばかりで知識ゼロの状態から、「広報とは?」という問いに答えてもらうところからスタートしました。
今では、社内環境のAI(Copilotや社内独自のAI)と業務を進めつつ、ChatGPTやPerplexity、FeloなどのAIとも日々会話しながら働いています。
自然言語でアバウトに聞いても、潜在ニーズを汲み取ってくれたり、
マーケティングツールの使い方を聞いたらマニュアル表を作ってくれたり――
一緒に業務を進めてくれる存在としてのAIに、すっかり魅了されています。
たまにちんぷんかんぷんなことを言ったり、強烈なギャグを挟んでくるところも大好きです(笑)
ローカルLLMに挑戦した理由
そんな中、今年8月に「gpt-oss」というOSSプロジェクトの発表を知りました。
ChatGPTが大好きな私は、OpenAIの動向を常にチェックしていて、すぐにChatGPTに「gpt-ossって何?」と聞いてみたところ...
ローカル環境でLLMを構築できるモデルが、フリーで使える!
ということが判明。
しかも、オフラインで動作し、プライバシーも守られ、自分好みのAIを作れるという点に心が躍りました。
今までは「そういうことができるのは技術者だけ」と思っていた領域。
でも、今ならAIと一緒に構築できるかもしれない――そう思って、ローカルLLM奮闘記が始まりました。
完全に個人の好奇心からのスタートでしたが、
P&Sには社員同士で自由に相談できる環境があり、身近にエンジニアの方もいるので、
「困ったら聞いてみよう」と思えたことも、踏み出すきっかけになりました。
ローカル環境の準備と"落とし穴"
さっそく環境構築に着手。社用PC以外はPCを持っていなかったため新たに購入を決意!
ChatGPTにも相談しながら選んだのが、GEEKOM A5(Ryzen7 5800H / RAM16GB)というミニPCでした。
決め手は、高いコスパとスペックのバランス。ただし、「GPU非搭載?でもオトクだし小さくてカワイイ!」と軽く考えていたのが甘かった......。
💥 落とし穴:GPUがないと、量子化されたモデルしか動かせない!
量子化(Quantization)とは、モデルの重みを4bitや8bitの低精度に変換して、サイズやメモリ消費を抑える技術です。これによりGPUがなくてもLLMを動かせるようになります。
しかし、
- 応答の簡素化や精度の低下
- 多様な量子化形式(q4KM, q8_0 など)の選定に迷う
といった課題もあり、日本語対応モデルでは「ちょっと物足りないな」と感じる場面も......。
結果的に、「非量子化モデルはそもそも起動できない」と知った時の衝撃は大きかったです。
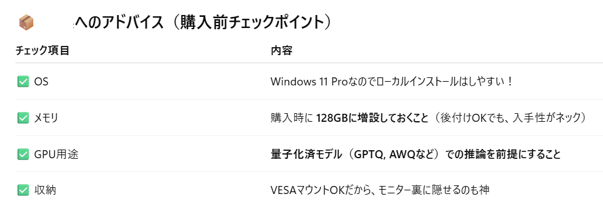
 ↑ちゃんと教えてくれていたのに、量子化を重要だと認識していなかった私のミスです(笑)
↑ちゃんと教えてくれていたのに、量子化を重要だと認識していなかった私のミスです(笑)
GEEKOM A5ではメモリも128GBは厳しい~!
モデル選定とUIツール
最初に使ってみたのは、KoboldCPP × OpenHermes。
gpt-ossを使用するつもりでしたが、なぜかChatGPTにOpenHermesの方が構築環境にあってるよ!と言われこちらに。
KoboldCPPはGGUF形式に対応した軽量なLLM実行ツールで、Windows上でも比較的手軽に導入できます。
ところが......
出力が"ドラゴン語(笑)"で、日本語にとても違和感を感じます...!

OpenHermesは日本語対応がやや苦手で、事前に言語サポートを確認せず使用したことが原因でした。
(あとでChatGPTに聞いたら、そうなの日本語苦手みたい~って言われて膝がガクッと崩れ落ちました(笑))
KoboldCPPだとドラゴンになってしまうので、次に試したのがLM StudioというローカルLLM用のUIツール。 GUIベースで、モデルの導入〜実行〜会話まで完結する点が非常に使いやすく、gpt-oss-20B(日本語対応モデル)を選んだところ、見事に会話成立!
コンテキスト制限とパラメータ調整
とはいえ、課題もありました。 キャラクター設定を含むプロンプトを使ったところ、わずか2往復で「コンテキスト満杯」エラーが......。
理由は、Context size: 4096 となってしまい、ハードウェアスペックによる制限が解除できないこと。
またキャラクターファイル(出力ルールや個性を記載したシステムプロンプト)の読み込みが恐らく原因。
なんとここでもPCスペックの壁が...(笑)
ケチらずに、頑張ってRAM:128GBを買うんだった...。
それでもなんとか方法を考え、パラメーター設定を以下に変更。
| パラメータ | 推奨値 | 目的 |
|---|---|---|
ctx-size |
8192 | 無理のない上限値に設定して、モデルの性能を引き出す |
max-new-tokens |
512 | 出力を短くして、生成をコンパクトに制御する |
temperature |
0.6〜0.8 | 生成のブレを抑えて、安定した出力を得る |
repetition-penalty |
1.1 | 同じ語尾や表現の繰り返しを防ぐ |
こうした"悪あがき"によって、
安定性を保ちながらより多くのラリーを継続できるようになりました。少しだけ(笑)
社内の知見に助けられる
思考錯誤しても難しいということが分かり、ローカルでの限界を感じはじめた頃、
P&SのエンジニアにSlackで相談したところ、エンジニアの方々がすかさず反応してくれました...そして。
「AWSなら、gpt-oss-120Bも動かせるかも?」
とのアドバイスをもらい、一気に視界が開けました!え、クラウドでgpt-oss?!
ローカルではどうしてもメモリや処理能力に限界がありますが、クラウド上であれば、より大規模なモデルにも挑戦可能。
AWSの会社に勤めておりながら、なぜその手を思いつかなかったのか...勉強しなおしてきます。
ということで、現在はAWS上でのgpt-oss実行環境の構築に向けて少しずつ奮闘中です。
まとめ
この技術チャレンジを通じて、以下の学びを得ました:
- GPU非搭載環境では量子化モデルが必須だが、精度には注意
- モデル選定では「日本語対応・量子化形式・コンテキスト長」を要チェック
- UIツール(KoboldCPP、LM Studio)で初心者も扱いやすくなる
- 社内の技術ナレッジは宝物!
- 本気でやりたいなら、PCはケチってはいけない(個人の感想です)
今回の挑戦を経て、技術に触れる面白さ、オーナーシップを持っている大切なP&Sの仲間の存在、それから...
広報として技術の世界に飛び込んでみて、AIはただの便利ツールではなく、改めて「共に創るパートナー」だと感じました。
次はクラウドでの大規模モデル運用に挑戦していきます!また次回お会いしましょう!
この記事は私が書きました
大野 萌梨
記事一覧