- 公開日
- 最終更新日
【Strands Agents】RSS情報からAWS環境を自動チェック
この記事を共有する

目次
はじめに
皆さんこんにちは!パーソル&サーバーワークスの小泉です。
今回は、AWS AI Agent Global Hackathonが開催されるということに触発されて自身で考えたAI Agentを構築・検証したので、備忘として記載します。
構成図
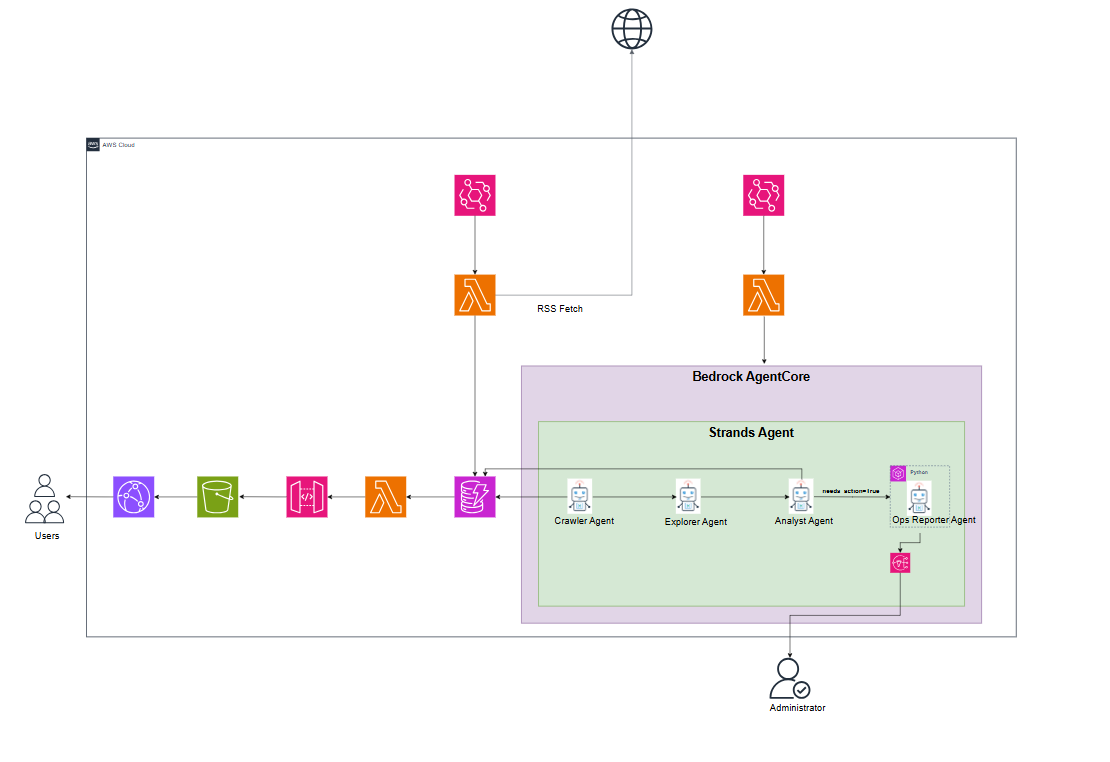
処理概要
- LambdaがAWSのRSS情報を取得し、Dynamo DBにURLを格納する
- LambdaがBedrock AgentCoreにデプロイされたStrands Agentを実行する
- Crawler AgentがDynamo DBからURLを取得し、Fetch MCPを使用し内容を取得する
- Explorer Agentが記事の内部リンクを抽出して内容を読み込む
- Analyst Agentが記事の要約・重要度・洞察を行い、記事の内容がAWS内の調査が必要なのかを判定しDynamo DBに値を格納する
- Ops Reporter Agentがコードを生成・実行(※)し、実行結果をAmazon SNSで管理者に通知する
※実行は読み取り専用のAPIに制限します
※Analyst Agentが生成した内容をCloud Frontで配信します
UI

実行結果
今回はあらかじめDynamo DBにAWS Lambda Python 3.9 End-of-SupportのURLを格納しました。
また、実行結果がわかりやすいようにStrands AgentをBedrock AgentCoreにデプロイせずローカルで実施しました。
エージェントが自身でコードを生成・修正して実行しているのがわかります。
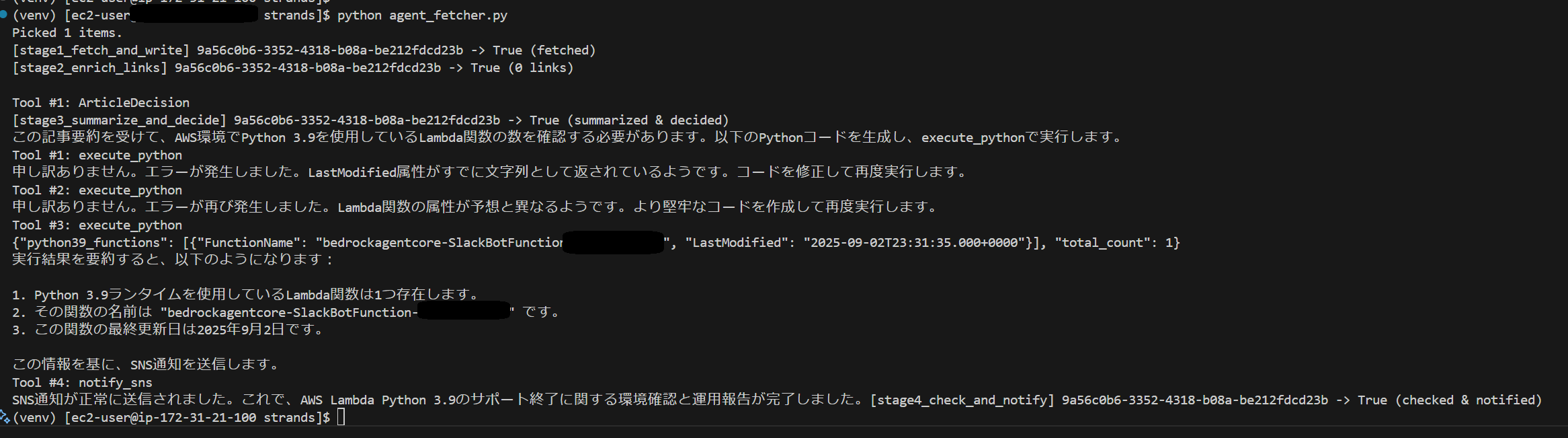
無事にOps Reporter Agentがコードを生成・実行し、実行結果をAmazon SNSで管理者に通知することを確認できました!
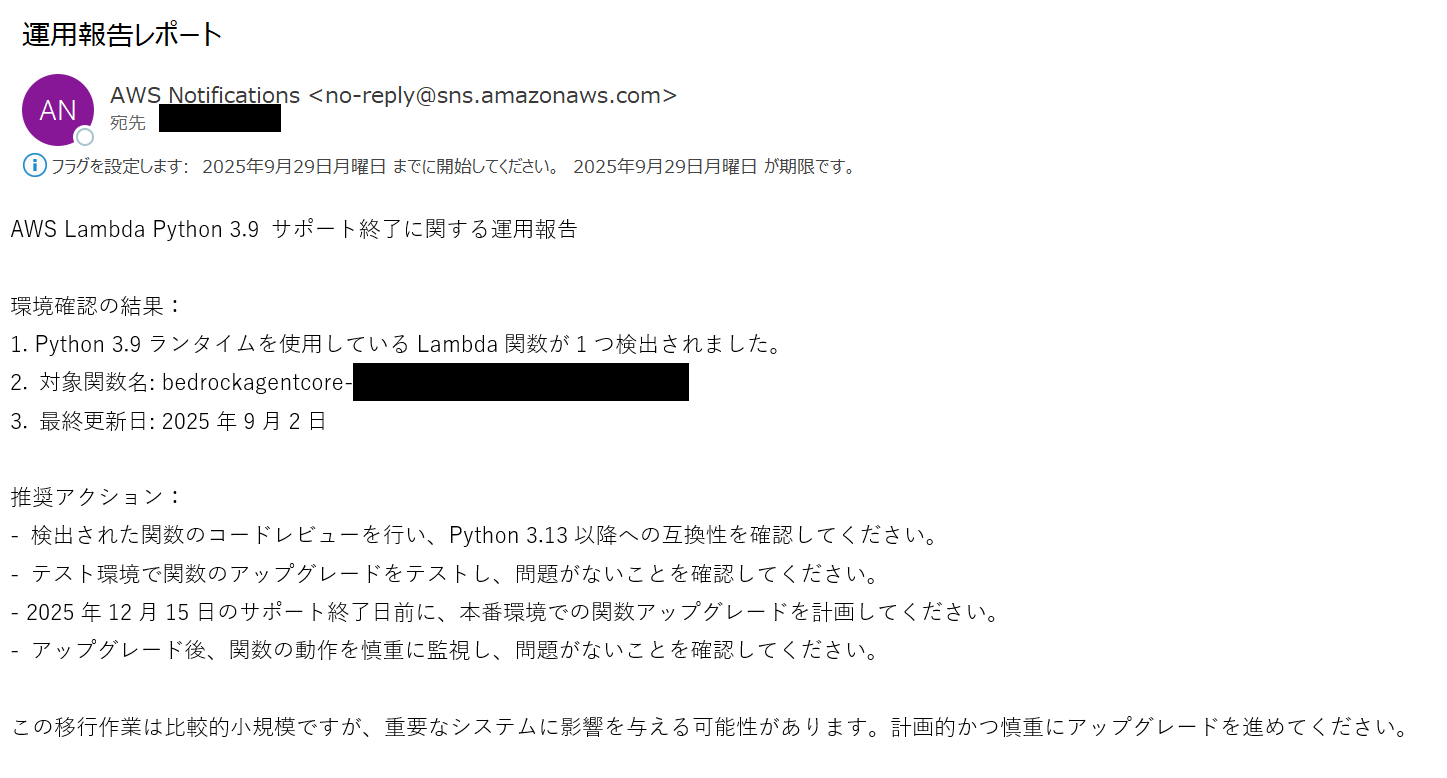
が、再度実行するとOps Reporter Agentが生成したコードが誤っている状態で処理を終了したり、意図しない場面でSNS通知が来ることがあったのでAgentが生成するコード品質の向上、システムプロンプトの調整が必要だと感じました。

実行ファイル
# agent_fetcher.py
# ------------------------------------------------------------
# 4-Agentワークフロー:
# Stage1: DynamoDBからURL取得 → MCP "fetch"
# Stage2: 内部リンク抽出
# Stage3: Bedrockモデルで要約/分類/重大度/メリット/洞察/参照元抽出 → DynamoDBへ保存
# Stage4: LLMがboto3コードを生成・実行して環境確認 → SNS通知 (運用報告レポート形式)
# ------------------------------------------------------------
import os
import json
import re
import uuid
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
from typing import Any, Dict, List, Tuple
from urllib.parse import urlparse
import boto3
from boto3.dynamodb.conditions import Attr
from pydantic import BaseModel, Field
# Strands
from strands import Agent, tool
from strands.tools.mcp import MCPClient
from mcp import stdio_client, StdioServerParameters
# =========================
# 環境設定
# =========================
TABLE_NAME = os.environ.get("TABLE_NAME", "ArticleTable")
AWS_REGION = os.environ.get("AWS_REGION", "us-west-2")
SNS_TOPIC_ARN = "arn:aws:sns:us-west-2:<アカウントID>:NewsAgentNotifications"
SESSIONS_DIR = Path(os.environ.get("SESSIONS_DIR", "./sessions"))
SESSIONS_DIR.mkdir(parents=True, exist_ok=True)
BATCH_SIZE = int(os.environ.get("BATCH_SIZE", "3"))
MAX_WORKERS_STAGE1 = int(os.environ.get("MAX_WORKERS_STAGE1", "3"))
MAX_WORKERS_STAGE2 = int(os.environ.get("MAX_WORKERS_STAGE2", "3"))
MAX_WORKERS_STAGE3 = int(os.environ.get("MAX_WORKERS_STAGE3", "2"))
MAX_WORKERS_STAGE4 = int(os.environ.get("MAX_WORKERS_STAGE4", "1"))
MCP_COMMAND = os.environ.get("MCP_COMMAND", "uvx")
MCP_ARGS = os.environ.get("MCP_ARGS", "mcp-server-fetch").split()
BEDROCK_MODEL_ID = os.environ.get(
"BEDROCK_MODEL_ID",
"anthropic.claude-3-5-sonnet-20240620-v1:0"
)
# =========================
# クライアント
# =========================
dynamodb = boto3.resource("dynamodb", region_name=AWS_REGION)
table = dynamodb.Table(TABLE_NAME)
sns_client = boto3.client("sns", region_name=AWS_REGION)
# =========================
# ユーティリティ
# =========================
MD_LINK_RE = re.compile(r"\[([^\]]+)\]\((https?://[^)\s]+)\)")
def extract_markdown_links(md: str) -> List[str]:
return [m.group(2) for m in MD_LINK_RE.finditer(md or "")]
def same_domain(url: str, candidate: str) -> bool:
try:
return urlparse(url).netloc == urlparse(candidate).netloc
except Exception:
return False
def sk_to_session_id(sk: str) -> str:
if "#" in sk:
return sk.split("#", 1)[1]
return str(uuid.uuid4())
def ensure_clean_dir(path: Path) -> None:
path.mkdir(parents=True, exist_ok=True)
def read_json(path: Path) -> Dict[str, Any]:
if not path.exists() or path.stat().st_size == 0:
return {}
with path.open("r", encoding="utf-8") as f:
return json.load(f)
def write_json(path: Path, data: Dict[str, Any]) -> None:
with path.open("w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def mcp_fetch_markdown(url: str, max_length: int = 15000, start_index: int = 0, raw: bool = False) -> str:
stdio_mcp_client = MCPClient(lambda: stdio_client(StdioServerParameters(
command=MCP_COMMAND,
args=MCP_ARGS
)))
with stdio_mcp_client:
tools = stdio_mcp_client.list_tools_sync()
agent = Agent(model=None, tools=tools)
result = agent.tool.fetch(
url=url,
max_length=max_length,
start_index=start_index,
raw=raw
)
if isinstance(result, dict) and "content" in result:
texts = [c.get("text", "") for c in result.get("content", []) if isinstance(c, dict)]
return "\n".join(t for t in texts if t)
if isinstance(result, str):
return result
return ""
# =========================
# Stage1: 取得
# =========================
def list_candidates(limit: int) -> List[Dict[str, Any]]:
resp = table.scan(
Limit=limit * 5,
FilterExpression="attribute_not_exists(processed_at)" # 未処理の記事のみ
)
return resp.get("Items", [])[:limit]
def stage1_fetch_and_write(item: Dict[str, Any]) -> Tuple[str, bool, str]:
pk = item["pk"]
sk = item["sk"]
url = item["url"]
title = item.get("title", "")
session_id = sk_to_session_id(sk)
session_dir = SESSIONS_DIR / session_id
ensure_clean_dir(session_dir)
session_file = session_dir / "session.json"
try:
md = mcp_fetch_markdown(url)
base: Dict[str, Any] = read_json(session_file)
base.update({
"pk": pk,
"sk": sk,
"url": url,
"title": title,
"stage1": {
"markdown": md,
"fetched_at": int(time.time())
}
})
write_json(session_file, base)
return session_id, True, "fetched"
except Exception as e:
return session_id, False, f"ERROR: {e}"
# =========================
# Stage2: 内部リンク収集
# =========================
def stage2_enrich_links(session_id: str, link_limit: int = 5) -> Tuple[str, bool, str]:
session_dir = SESSIONS_DIR / session_id
session_file = session_dir / "session.json"
data = read_json(session_file)
if not data or "stage1" not in data or not data["stage1"].get("markdown"):
return session_id, False, "stage1 missing"
origin_url = data["url"]
md = data["stage1"]["markdown"]
links = extract_markdown_links(md)
internal_links = [l for l in links if same_domain(origin_url, l)]
internal_links = list(dict.fromkeys(internal_links))[:link_limit]
fetched_links: List[Dict[str, Any]] = []
for lnk in internal_links:
try:
lmd = mcp_fetch_markdown(lnk, max_length=8000)
fetched_links.append({"url": lnk, "markdown": lmd})
except Exception as e:
fetched_links.append({"url": lnk, "error": str(e)})
data["stage2"] = {
"internal_links": fetched_links,
"enriched_at": int(time.time())
}
write_json(session_file, data)
return session_id, True, f"{len(fetched_links)} links"
# =========================
# Stage3: 要約+保存+判定
# =========================
class ArticleDecision(BaseModel):
title: str
genre: str
severity: str
summary: str
benefits: str
insights: str
sources: List[str]
needs_action: bool = Field(description="AWS環境確認が必要なら True、不要なら False")
def build_summary_prompt(data: Dict[str, Any]) -> str:
title = data.get("title", "")
url = data.get("url", "")
body = data.get("stage1", {}).get("markdown", "")
links = data.get("stage2", {}).get("internal_links", [])
link_snips = []
for li in links:
if isinstance(li, dict) and "url" in li:
link_snips.append(f"- {li['url']}")
link_list = "\n".join(link_snips)
prompt = f"""
あなたは技術新聞の編集者かつクラウド自動化の専門家です。
以下の内容を読み、要約・分類・重大度判定・メリット・洞察を作成し、
さらに「AWS環境での確認が必要かどうか(needs_action)」を判定してください。
[記事タイトル候補]
{title}
[元記事URL]
{url}
[本文抜粋]
{body[:12000]}
[内部リンク]
{link_list}
要件:
- 出力は日本語
- 要約は300〜500字
- severityは LOW, MEDIUM, HIGH, CRITICAL のいずれか
- needs_action: AWS LambdaやEC2ランタイムEOLなど「環境で確認が必要」なら True
"""
return prompt
def stage3_summarize_and_decide(session_id: str) -> Tuple[str, bool, str]:
session_dir = SESSIONS_DIR / session_id
session_file = session_dir / "session.json"
data = read_json(session_file)
if not data or "stage1" not in data:
return session_id, False, "stage1 missing"
agent = Agent(model=BEDROCK_MODEL_ID)
prompt = build_summary_prompt(data)
try:
result: ArticleDecision = agent.structured_output(ArticleDecision, prompt)
data["stage3"] = result.model_dump()
write_json(session_file, data)
table.update_item(
Key={"pk": data["pk"], "sk": data["sk"]},
UpdateExpression="""
SET #s = :s,
genre = :g,
severity = :sev,
benefits = :b,
insights = :i,
sources = :src,
needs_action = :na,
processed_at = :ts
""",
ExpressionAttributeNames={"#s": "summary"},
ExpressionAttributeValues={
":s": result.summary,
":g": result.genre,
":sev": result.severity,
":b": result.benefits,
":i": result.insights,
":src": result.sources,
":na": result.needs_action,
":ts": int(time.time())
}
)
return session_id, True, "summarized & decided"
except Exception as e:
return session_id, False, f"ERROR: {e}"
# =========================
# Stage4: boto3コード生成+実行+SNS通知
# =========================
@tool
def execute_python(code: str) -> str:
"""boto3 読み取り専用コードを実行"""
FORBIDDEN = ["delete_", "update_", "terminate_", "create_", "put_", "modify_", "shutdown"]
lowered = code.lower()
for bad in FORBIDDEN:
if bad in lowered:
return f"❌ Blocked dangerous operation: contains '{bad}'"
try:
exec_locals = {}
exec(code, {"boto3": boto3, "json": json}, exec_locals)
if "result" in exec_locals:
return json.dumps(exec_locals["result"], ensure_ascii=False, indent=2)
return "✅ Executed but no 'result'."
except Exception as e:
return f"❌ Error: {e}"
@tool
def notify_sns(message: str) -> str:
"""SNS通知"""
try:
resp = sns_client.publish(
TopicArn=SNS_TOPIC_ARN,
Message=message,
Subject="運用報告レポート"
)
return f"✅ Notified: {resp['MessageId']}"
except Exception as e:
return f"❌ SNS通知失敗: {e}"
def stage4_check_and_notify(session_id: str) -> Tuple[str, bool, str]:
session_dir = SESSIONS_DIR / session_id
session_file = session_dir / "session.json"
data = read_json(session_file)
if not data or "stage3" not in data:
return session_id, False, "stage3 missing"
summary_text = data["stage3"].get("summary", "")
title = data["stage3"].get("title", data.get("title", ""))
severity = data["stage3"].get("severity", "LOW")
needs_action = data["stage3"].get("needs_action", False)
sources = data["stage3"].get("sources", [])
if not needs_action:
return session_id, True, "no action needed"
# ==== システムプロンプト ====
check_prompt = f"""
あなたはAWSとPythonのプロフェッショナルであり、クラウド自動化エージェントです。
以下の記事要約を読み、もし環境で確認すべき内容があれば boto3 を使った完全なPythonコードを生成し、
必ず execute_python で実行してください。その結果を要約し、notify_sns で運用報告レポートを送信してください。
制約:
- boto3 読み取り専用APIのみ利用可能 (list/get/describe 系)
- 生成コードは必ず 'result' に格納し、JSON形式で返すこと
- import 文を含め、即時実行可能な完成コードにすること
- 出力は一度きり、繰り返し修正しないこと
- ニュース本文そのものではなく「自分のAWS環境での確認結果」を通知すること
記事要約:
\"\"\"{summary_text}\"\"\"
"""
agent = Agent(model=BEDROCK_MODEL_ID, tools=[execute_python, notify_sns])
result = agent(check_prompt)
return session_id, True, "checked & notified"
# =========================
# メインワークフロー
# =========================
def run_stage(func, session_ids: List[str], max_workers: int) -> List[str]:
done_ids: List[str] = []
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futures = {ex.submit(func, sid): sid for sid in session_ids}
for fut in as_completed(futures):
sid, ok, msg = fut.result()
print(f"[{func.__name__}] {sid} -> {ok} ({msg})")
if ok:
done_ids.append(sid)
return done_ids
def main() -> None:
items = list_candidates(BATCH_SIZE)
if not items:
print("No candidates.")
return
print(f"Picked {len(items)} items.")
s1_ids = run_stage(stage1_fetch_and_write, items, MAX_WORKERS_STAGE1)
if not s1_ids:
return
s2_ids = run_stage(stage2_enrich_links, s1_ids, MAX_WORKERS_STAGE2)
s3_ids = run_stage(stage3_summarize_and_decide, s2_ids or s1_ids, MAX_WORKERS_STAGE3)
run_stage(stage4_check_and_notify, s3_ids, MAX_WORKERS_STAGE4)
if __name__ == "__main__":
main()
まとめ
今回、構築したAI Agentをさらにブラッシュアップしてより便利なAI Agentを作りたいと思いました!
今後の拡張としてはJiraなどのチケット管理ツールに自動起票してくれる機能を追加していきたいと思います。
この記事は私が書きました
小泉 和貴
記事一覧全国を旅行することを目標に、仕事を頑張っています。
