- 公開日
- 最終更新日
【Bedrock】クロスリージョン推論によるスロットリングエラー回避
この記事を共有する
目次
はじめに
こんにちは、P&Sの村上です。
最近、Amazon Bedrockで基盤モデルの検証をしていた際に、下記スロットリングエラーに遭遇したのでクロスリージョン推論を用いた回避策についてご紹介します。
An error occurred (ThrottlingException) when calling the InvokeModel operation (reached max retries: 4): Too many requests, please wait before trying again.
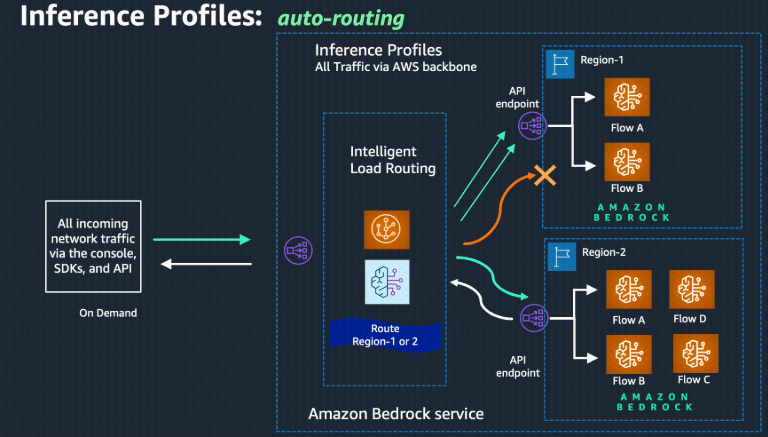
クロスリージョン推論とは
Amazon Bedrockの機能の1つで、複数のリージョンのモデルの負荷状況を考慮して利用可能なリージョンのモデルを選択してくれる機能になります。
単一リージョンでAmazon Bedrockにモデルリクエストを行い、クォータを超えるリクエストでスロットリングエラーが発生した場合、利用可能になるまで待つ必要があります。
そこでクロスリージョン推論を利用することで、東京リージョンでスパイクが発生した場合でも、利用可能な別リージョンへ推論リクエストがルーティングされてスロットリングエラーを回避することが出来ます。
推論プロファイルに対してリクエストを行うことで、プロファイルに紐づく地理的グループ(アメリカ地域、ヨーロッパ地域、アジア地域)内リージョンの負荷状況を考慮して適切なリージョンにルーティングされます。
 Getting started with cross-region inference in Amazon Bedrock
Getting started with cross-region inference in Amazon Bedrock
やりたいこと
- EC2インスタンスからAmazon Bedrock Claude 3.5 Sonnetへ推論リクエストを実施
- クロスリージョン推論でリクエストを行った際にスロットリングエラーが出ないことを確認
プロジェクト構成
下記が今回のプロジェクトの構成になります。
bedrock
├── test_cross_region_inference.py # テストリクエスト用Pythonファイル
├── requirements.txt
├── test_results_single_region_{yyyymmdd}_{hhmmss}.json # テスト結果(単一リージョン)
└── test_results_cross_region_{yyyymmdd}_{hhmmss}.json # テスト結果(複数リージョン)
検証手順
検証は下記に分けて実施していきます。
- 準備
- Amazon Bedrock Claude 3.5 Sonnet(東京リージョンのみ)へ推論リクエスト
- Amazon Bedrock Claude 3.5 Sonnet(アジア地域リージョン)へクロスリージョン推論でのリクエスト
- CloudWatch で挙動の確認
1. 準備
プロジェクトの作成
プロジェクトのディレクトリを作成します。
mkdir -p ~/Developments/bedrock & cd ~/Developments/bedrock
テスト用Pythonファイル
test_cross_region_inference.py
import boto3
import json
import time
import argparse
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor
from typing import List, Dict, Any
import logging
from botocore.exceptions import ClientError
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class CrossRegionInferenceTest:
def __init__(self, mode: str = 'cross-region'):
self.mode = mode
self.inference_profile_id = 'apac.anthropic.claude-3-5-sonnet-20240620-v1:0'
self.single_region_model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
self.primary_region = 'ap-northeast-1'
self.clients = {}
self.initialize_clients()
def initialize_clients(self):
try:
self.clients[self.primary_region] = boto3.client('bedrock-runtime', region_name=self.primary_region)
logger.info(f"Initialized Client for region: {self.primary_region}")
except Exception as e:
logger.error(f"Failed to initialize client for region {self.primary_region}: {e}")
def create_test_message(self, request_id: int) -> str:
prompt = 'こんにちは'
return prompt
def invoke_model(self, region: str, request_id: int) -> Dict[str, Any]:
try:
client = self.clients[region]
message = self.create_test_message(request_id)
body = {
'anthropic_version': 'bedrock-2023-05-31',
'max_tokens': 1000,
'messages': [
{
'role': 'user',
'content': message
}
]
}
# 推論モードの選択
model_id = self.inference_profile_id if self.mode == 'cross-region' else self.single_region_model_id
start_time = time.time()
response = client.invoke_model(
body=json.dumps(body),
modelId=model_id,
contentType='application/json',
accept='application/json'
)
end_time = time.time()
response_body = json.loads(response['body'].read())
full_response = response_body['content'][0]['text']
# レスポンス表示
print(f"\n{'='*60}")
print(f"[Request #{request_id}] Response time: {end_time - start_time:.2f}s")
print(f"Promt: こんにちは")
print(f"Output: {full_response}")
print(f"{'='*60}\n")
return {
'request_id': request_id,
'region': region,
'mode': self.mode,
'model_id': model_id,
'success': True,
'response_time': end_time - start_time,
'timestamp': datetime.now().isoformat(),
'content': full_response
}
except ClientError as e:
error_code = e.response['Error']['Code']
error_message = str(e)
# レスポンス表示
print(f"\n{'='*60}")
print(f"Promt: こんにちは")
print(f"Error Code: {error_code}")
print(f"Error Message: {error_message}")
if error_code in ['ThrottlingException', 'ServiceQuotaExceededException']:
print(f"[QUOTA/THROTTLING ERROR] Request rate limit exceeded!")
print(f"[Request #{request_id}] FAILED")
print(f"{'='*60}\n")
return {
'request_id': request_id,
'region': region,
'success': False,
'error_code': error_code,
'error_message': error_message,
'timestamp': datetime.now().isoformat(),
'is_quota_exceeded': error_code in ['ThrottlingException', 'ServiceQuotaExceededException']
}
except Exception as e:
error_message = str(e)
return {
'request_id': request_id,
'region': region,
'success': False,
'error_message': str(e),
'timestamp': datetime.now().isoformat(),
'is_quota_exceeded': False
}
def invoke_in_parallel(self, region: str, num_requests: int, target_duration: float = 60.0) -> List[Dict[str, Any]]:
target_rate = num_requests / (target_duration / 60) # リクエスト/分
interval = target_duration / num_requests # リクエスト間隔
logger.info(f"Starting RATE LIMITED TEST: {num_requests} requests to {region} over {target_duration:.1f}s")
logger.info(f"Target rate: {target_rate:.1f} requests/minute (interval: {interval:.2f}s)")
start_time = time.time()
with ThreadPoolExecutor() as executor:
futures = []
for i in range(num_requests):
target_submit_time = start_time + (i * interval)
current_time = time.time()
if current_time < target_submit_time:
time.sleep(target_submit_time - current_time)
future = executor.submit(self.invoke_model, region, i + 1)
futures.append(future)
if (i + 1) % 10 == 0 or i == 0:
elapsed = time.time() - start_time
current_rate = ((i + 1) / elapsed) * 60 if elapsed > 0 else 0
logger.info(f"Submitted: {i + 1}/{num_requests} requests. Current rate: {current_rate:.1f} req/min")
results = []
completed = 0
for future in futures:
result = future.result()
results.append(result)
completed += 1
if result['success']:
logger.info(f"✅ Request {result['request_id']}/{num_requests} to {region}: SUCCESS (response_time: {result.get('response_time', 0):.2f}s)")
else:
logger.warning(f"❌ Request {result['request_id']}/{num_requests} to {region}: FAILED - {result.get('error_code', 'Unknown')}")
if completed % 10 == 0:
elapsed = time.time() - start_time
current_rate = (completed / elapsed) * 60 if elapsed > 0 else 0
logger.info(f"Completed: {completed}/{num_requests}. Current rate: {current_rate:.1f} req/min")
total_duration_actual = time.time() - start_time
actual_rate = (num_requests / total_duration_actual) * 60 if total_duration_actual > 0 else 0
logger.info(f"RATE LIMITED TEST COMPLETED: {num_requests} requests in {total_duration_actual:.2f}s")
logger.info(f"Actual rate: {actual_rate:.1f} requests/minute")
return results
def analyze_results(self, results: List[Dict[str, Any]]) -> Dict[str, Any]:
total_requests = len(results)
successful_requests = sum(1 for r in results if r['success'])
failed_requests = total_requests - successful_requests
quota_exceeded_requests = sum(1 for r in results if r.get('is_quota_exceeded', False))
successful_response_times = [r['response_time'] for r in results if r['success'] and 'response_time' in r]
avg_response_time = sum(successful_response_times) / len(successful_response_times) if successful_response_times else 0
error_codes = {}
for r in results:
if not r['success'] and 'error_code' in r:
error_code = r['error_code']
error_codes[error_code] = error_codes.get(error_code, 0) + 1
return {
'total_requests': total_requests,
'successful_requests': successful_requests,
'failed_requests': failed_requests,
'quota_exceeded_requests': quota_exceeded_requests,
'success_rate': successful_requests / total_requests * 100,
'avg_response_time': avg_response_time,
'error_codes': error_codes
}
def test_cross_region_inference(self, initial_requests: int = 190, target_duration: float = 60.0):
logger.info('=== Starting Cross-Region Inference Test ===')
logger.info(f"Mode: {self.mode}")
logger.info(f"Inference Profile ID: {self.inference_profile_id}")
logger.info(f"Primary region: {self.primary_region}")
logger.info("Cross-region inference will be handled automatically by the ifnerence profile")
target_rate = initial_requests / (target_duration / 60)
logger.info(f"\n=== RATE LIMITED TESTING inference profile with {initial_requests} requests over {target_duration}s (target: {target_rate:.1f} req/min) ===")
results = self.invoke_in_parallel(self.primary_region, initial_requests, target_duration)
analysis = self.analyze_results(results)
logger.info(f"Inference profile results:")
logger.info(f" Success rate: {analysis['success_rate']:.1f}%")
logger.info(f" Avg response time: {analysis['avg_response_time']:.2f}%")
logger.info(f" Quota exceeded requests: {analysis['quota_exceeded_requests']}")
logger.info(f" Error codes: {analysis['error_codes']}")
if analysis['quota_exceeded_requests'] > 0:
logger.info('\nQuota exceeded detected - the inference profile should automatically route to available regions')
else:
logger.info('\nAll requests completed successfully through the inference profile')
logger.info(f"\n=== Test Summary ===")
logger.info(f"Test completed at: {datetime.now().isoformat()}")
logger.info(f"Inference Profile ({self.inference_profile_id}) - Success rate: {analysis['success_rate']:.1f}%")
return {
'mode': self.mode,
'inference_profile_id': self.inference_profile_id,
'primary_region': self.primary_region,
'results': analysis,
'time_timestamp': datetime.now().isoformat()
}
def test_single_region_inference(self, initial_requests: int = 20, target_duration: float = 60.0):
logger.info('=== Starting Single Region RATE LIMITED TEST ===')
logger.info(f"Mode: {self.mode}")
logger.info(f"Model ID: {self.single_region_model_id}")
logger.info(f"Target region: {self.primary_region}")
target_rate = initial_requests / (target_duration / 60)
logger.info(f"Testing with {initial_requests} requests over {target_duration}s")
logger.info('All requests will be sent directly to ap-northeast-1 Claude 3.5 Sonnet with rate limiting')
logger.info(f"\n=== RATE LIMITED TESTING single region with {initial_requests} requests over {target_duration}s ===")
results = self.invoke_in_parallel(self.primary_region, initial_requests, target_duration)
analysis = self.analyze_results(results)
logger.info('Single region results:')
logger.info(f" Success rate: {analysis['success_rate']:.1f}%")
logger.info(f" Successful requests: {analysis['successful_requests']}/{analysis['total_requests']}")
logger.info(f" Avg response time: {analysis['avg_response_time']:.2f}s")
logger.info(f" Quota exceeded requests: {analysis['quota_exceeded_requests']}")
logger.info(f" Error codes: {analysis['error_codes']}")
if analysis['quota_exceeded_requests'] > 0:
logger.warning(f"\n QUOTA LIMITE REACHED! {analysis['quota_exceeded_requests']} requests failed due to quota/throttling limits")
else:
logger.info(f"\n All {analysis['total_requests']} requests completed successfully in single region")
# レポート表示
logger.info(f"\n=== Test Summary ===")
logger.info(f"Test completed at: {datetime.now().isoformat()}")
logger.info(f"Single Region ({self.single_region_model_id}) - Success rate: {analysis['success_rate']:.1f}%")
return {
'mode': self.mode,
'model_id': self.single_region_model_id,
'primary_region': self.primary_region,
'results': analysis,
'test_timestamp': datetime.now().isoformat()
}
def run_test(self, initial_requests: int = None, target_duration: float = 60.0):
if initial_requests is None:
initial_requests = 20 if self.mode == 'single-region' else 190
if self.mode == 'cross-region':
return self.test_cross_region_inference(initial_requests, target_duration)
elif self.mode == 'single-region':
return self.test_single_region_inference(initial_requests, target_duration)
else:
raise ValueError(f"Invalid mode: {self.mode}. Must be 'cross-region' or 'single-region'")
def main():
parser = argparse.ArgumentParser(
description='Amazon Bedrock Claude 3.5 Sonnet Cross-Region Inference Test',
formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument('--mode', choices=['cross-region', 'single-region'], default='cross-region',)
parser.add_argument('--requests', type=int, default=None)
parser.add_argument('--duration', type=float, default=60.0)
args = parser.parse_args()
if args.requests is None:
args.requests = 190 if args.mode == 'cross-region' else 20
# 設定の表示
target_rate = args.requests / (args.duration / 60)
logger.info('Configuration')
logger.info(f" Mode: {args.mode}")
logger.info(f" Requests: {args.requests}")
logger.info(f" Duration: {args.duration}s")
logger.info(f" Target Rate: {target_rate:.1f} requests/minute")
logger.info(f" Rate Limited Test: Requests spread over {args.duration}")
# テストインスタンス作成
tester = CrossRegionInferenceTest(mode=args.mode)
# テスト実行
try:
results = tester.run_test(
initial_requests=args.requests,
target_duration=args.duration
)
print(f"Test Completed!")
print(f" Total requests: {results.get('results', {}).get('total_requests', 'N/A')}")
print(f" Success rate: {results.get('results', {}).get('success_rate', 0):.1f}%")
if results.get('results', {}).get('quota_exceeded_requests', 0) > 0:
print(f" ⚠️ Quota exceeded: {results.get('results', {}).get('quota_exceeded_requests')} requests")
else:
print(f" ✅ No quota limits reached")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"test_results_{args.mode.replace('-', '_')}_{timestamp}.json"
with open(filename, 'w', encoding='utf-8') as f:
json.dump(results, f, indent=2, ensure_ascii=False)
logger.info(f"Results saved to: {filename}")
except Exception as e:
logger.error(f"Test failed with error: {e}")
raise
if __name__ == "__main__":
main()
ライブラリのインストール
ローカル環境での検証に必要なライブラリをインストールします。
boto3==1.40.23
botocore==1.40.23
jmespath==1.0.1
python-dateutil==2.9.0.post0
s3transfer==0.13.1
six==1.17.0
urllib3==2.5.0
python -m venv ~/.venv/test-cross-region-inference
source ~/.venv/test-cross-region-inference/bin/activate
pip -r requirements.txt
IAMポリシーの設定
各リージョンのClaude 3.5 Sonnetに対してクロスリージョン推論を行うため、権限追加を行います。
EC2に設定しているIAMロールに下記内容のポリシーを追加してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": [
"arn:aws:bedrock:ap-northeast-1:{accountId}:inference-profile/apac.anthropic.claude-3-5-sonnet-20240620-v1:0",
"arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0",
"arn:aws:bedrock:ap-northeast-2::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0",
"arn:aws:bedrock:ap-southeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0",
"arn:aws:bedrock:ap-southeast-2::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0",
"arn:aws:bedrock:ap-south-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0"
]
}
]
}
CloudWatch Logsグループの作成
Amazon Bedrockのモデル呼び出しの利用状況確認のため、CloudWatch Logsグループを作成します。
コンソール画面>CloudWatch>ロググループ>ロググループを作成から、下記設定でロググループを作成してください。
※その他の設定はデフォルトのままとします。
- ロググループ名: bedrock-cross-region-logs
- 保持期間の設定: 1日
モデル呼び出しのログ記録 有効化
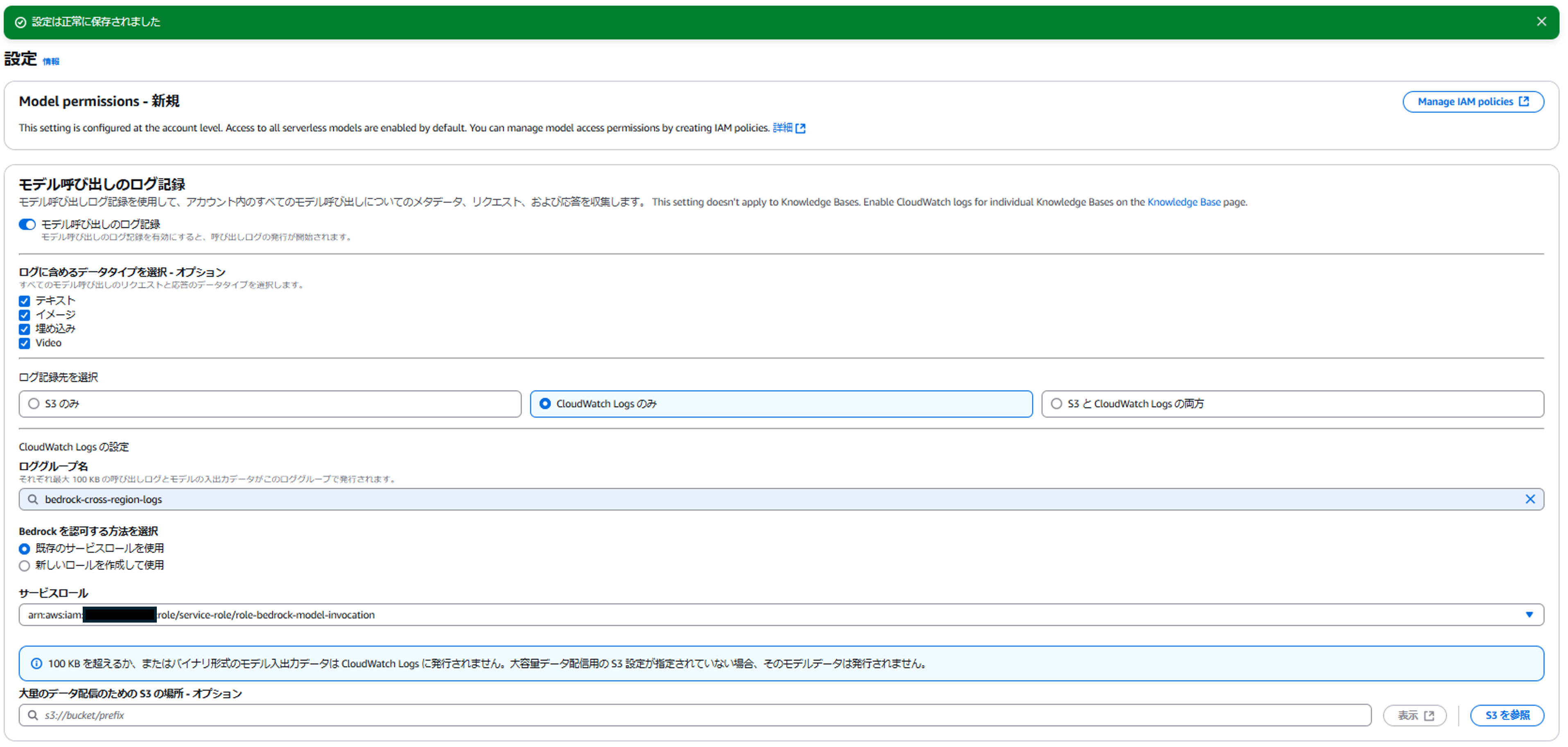
Amazon Bedrockのモデル呼び出しの利用状況確認のため、Amazon Bedrockでログ記録を有効化します。
コンソール画面>Amazon Bedrock>設定>「モデル呼び出しのログ記録」から、下記設定で保存してください。
※その他の設定はデフォルトのままとします。
- モデル呼び出しのログ記録: 有効化
- ログ記録先を選択: CloudWatch Logsのみ
- ロググループ名: bedrock-cross-region-logs
- Bedrockを認可する方法を選択: 新しいサービスロールを作成して使用
- サービスロール名: role-bedrock-model-invocation
※新しいロールを作成して使用するを選択した場合、1回目の設定保存で失敗します。
ページ更新後にIAMロールの作成は成功しているので、「Bedrockを認可する方法を選択」を下記のように変更して再度設定保存を行ってください。
- モデル呼び出しのログ記録: 有効化
- ログ記録先を選択: CloudWatch Logsのみ
- ロググループ名: bedrock-cross-region-logs
- Bedrockを認可する方法を選択: 既存のサービスロールを使用
- サービスロール名: role-bedrock-model-invocation
2. Amazon Bedrock Claude 3.5 Sonnet(東京リージョンのみ)へ推論リクエスト
事前準備が出来ましたので、まずは東京リージョンのみでClaude 3.5 Sonnetに対して、1分間で25リクエストになるように下記コマンドで推論リクエストを実行します。
今回はリクエストのクォータによるスロットリングを回避出来るかを確認するため、「こんにちは」というシンプルなプロンプトでリクエストを行います。
python test_cross_region_inference.py --mode single-region --requests 25 --duration 60
結果
リクエスト終了後に、出力されたtest_results_single_region_{yyyymmdd}_{hhmmss}.jsonを見てみると、いくつかのリクエストでスロットリングエラーが発生して失敗していることが確認出来ます。
{
"mode": "single-region",
"model_id": "anthropic.claude-3-5-sonnet-20240620-v1:0",
"primary_region": "ap-northeast-1",
"results": {
"total_requests": 25,
"successful_requests": 17,
"failed_requests": 8,
"quota_exceeded_requests": 8,
"success_rate": 68.0,
"avg_response_time": 2.671551185495713,
"error_codes": {
"ThrottlingException": 8
}
},
"test_timestamp": "2025-09-05T00:35:44.532606"
}
3. Amazon Bedrock Claude 3.5 Sonnet(アジア地域リージョン)へクロスリージョン推論でのリクエスト
続いて、クロスリージョン推論でClaude 3.5 Sonnetに対して、先ほどと同じく1分間で25リクエストになるように下記コマンドで推論リクエストを実行します。
python test_cross_region_inference.py --mode cross-region --requests 25 --duration 60
単一リージョンのモデルへの推論リクエストとクロスリージョン推論での推論リクエストはinvoke_modelメソッドのmodelIdパラメータで制御しています。
modelIdにanthropic.claude-3-5-sonnet-20240620-v1:0を指定した場合は単一リージョンのモデルへの推論リクエストとなり、apac.anthropic.claude-3-5-sonnet-20240620-v1:0を指定した場合はクロスリージョン推論で複数リージョンのモデルへの推論リクエストが行われます。
def invoke_model(self, region: str, request_id: int) -> Dict[str, Any]:
.
.
.
response = client.invoke_model(
body=json.dumps(body),
modelId=model_id,
contentType='application/json',
accept='application/json'
)
結果
リクエスト終了後に、出力されたtest_results_cross_region_{yyyymmdd}_{hhmmss}.jsonを見てみると、さきほどはスロットリングエラーで失敗していたリクエストが全て成功していることが確認出来ます。
{
"mode": "cross-region",
"inference_profile_id": "apac.anthropic.claude-3-5-sonnet-20240620-v1:0",
"primary_region": "ap-northeast-1",
"results": {
"total_requests": 25,
"successful_requests": 25,
"failed_requests": 0,
"quota_exceeded_requests": 0,
"success_rate": 100.0,
"avg_response_time": 1.4839871883392335,
"error_codes": {}
},
"time_timestamp": "2025-09-05T05:34:37.575875"
}
4. CloudWatch で挙動の確認
先ほどモデル呼び出しのログ記録を有効化したので、CloudWatch Logsにモデルへのリクエスト情報が記録されます。
CloudWatchのロググループとログインサイトを使って、クロスリージョン推論が機能しているかを確認してみます。
ロググループ
コンソール画面>CloudWatch>ロググループ>bedrock-cross-region-logs>から下記最新のログを見るとinferenceRegionがap-northeast-2(ソウルリージョン)となっていることがわかります。
推論リクエストログ
{
"timestamp": "2025-09-05T05:34:36Z",
"accountId": "{accountId}",
"identity": {
"arn": "arn:aws:sts::{accountId}:assumed-role/{roleName}/i-06253be2da71ddcb0"
},
"region": "ap-northeast-1",
"requestId": "e710f5bc-352c-40bb-8679-cb811914b8c9",
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:ap-northeast-1:{accountId}:inference-profile/apac.anthropic.claude-3-5-sonnet-20240620-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "こんにちは"
}
]
},
"inputTokenCount": 12
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"id": "msg_bdrk_016BwvEK5goWc7HxGyJKqkVP",
"type": "message",
"role": "assistant",
"model": "claude-3-5-sonnet-20240620",
"content": [
{
"type": "text",
"text": "こんにちは!お元気ですか?何かお手伝いできることはありますか?"
}
],
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 12,
"output_tokens": 30
}
},
"outputTokenCount": 30
},
"inferenceRegion": "ap-northeast-2", # <- 推論リクエストを処理したモデルのリージョン
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
ログインサイトでの確認
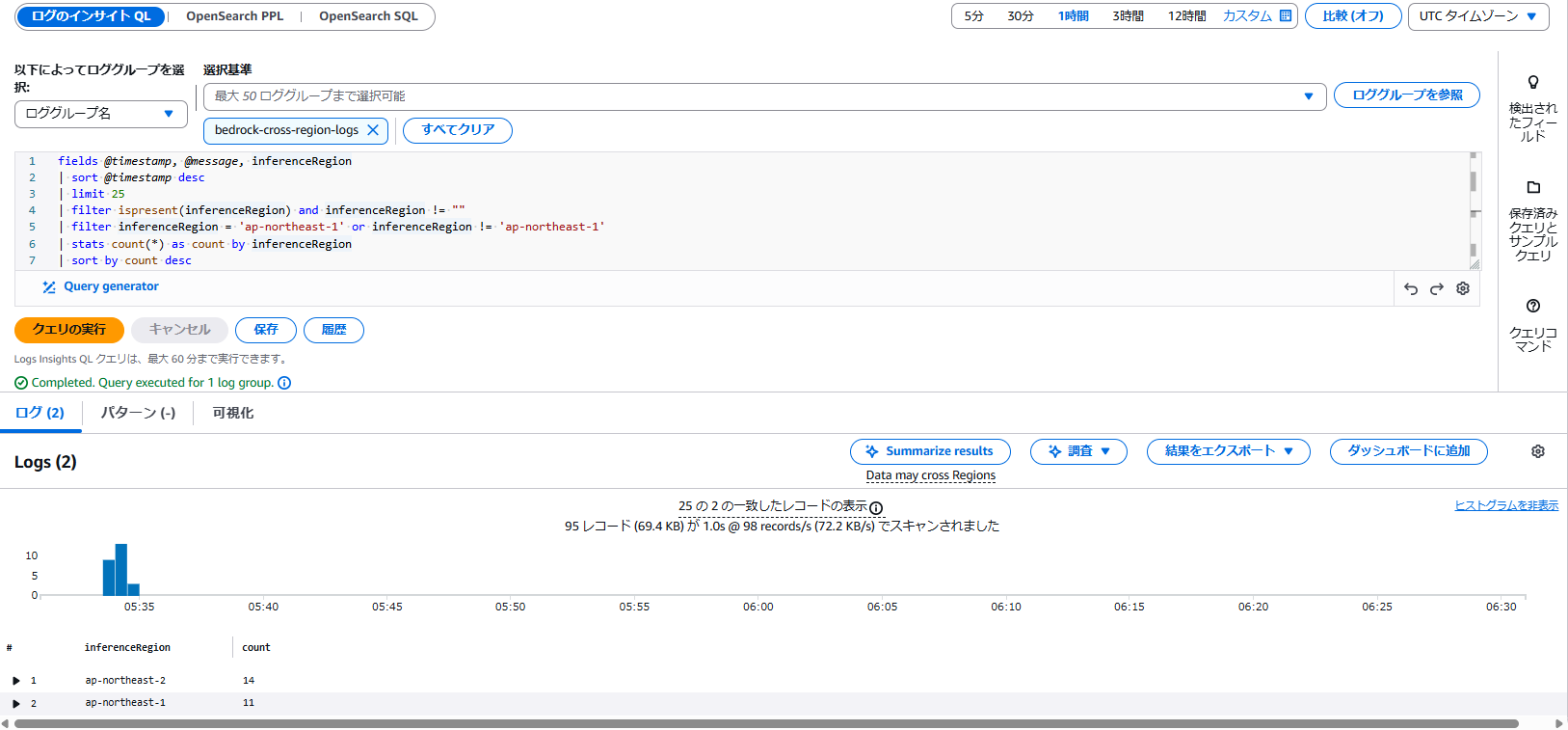
コンソール画面>CloudWatch>ログインサイトにてロググループ名にbedrock-cross-region-logsを指定して下記クエリを実行してみます。
fields @timestamp, @message, inferenceRegion
| sort @timestamp desc
| limit 25
| filter ispresent(inferenceRegion) and inferenceRegion != ""
| filter inferenceRegion = 'ap-northeast-1' or inferenceRegion != 'ap-northeast-1'
| stats count(*) as count by inferenceRegion
| sort by count desc
下記クエリ結果から、ap-northeast-1(東京)以外にap-northeast-2(ソウル)へ推論リクエストが一定量送られていることから、ログベースでもクロスリージョン推論が機能していることが確認出来ました。
まとめ
Amazon Bedrockでは、基盤モデルを簡単に素早く利用することが出来ますが、アプリケーション導入時にはクォータを気にしておく必要があります。
アプリケーションへのスパイク発生時など、スロットリングエラー対策として本記事が参考になれば幸いです!
この記事は私が書きました
村上 大地
記事一覧筋トレとサウナの合間にDevOpsを学んでいます。
