- 公開日
- 最終更新日
【AWS re:Invent 2025】AIエージェント基盤 MCP × Kiro× AgentCore 徹底解説
この記事を共有する

目次
re:Invent2025では、AWSがAIのどこで勝負するのかが明確になりました。 Keynoteと「Building AI Agents with Kiro, MCP, and Amazon Bedrock AgentCore (DEV331)」で繰り返し強調されていたのは、企業がAIエージェントを安全に・大規模に運用できる基盤を整備するという方向性です。
AWSのAI戦略は、モデル競争からAIエージェント実行基盤へ重心が移りつつある
セッション序盤で提示されたのが、 AIアシスタント(Generative AI assistants) → エージェント(Generative AI agents) → マルチエージェントシステム(Agentic AI systems) への進化の図です。

改めて、AIエージェントとは何か
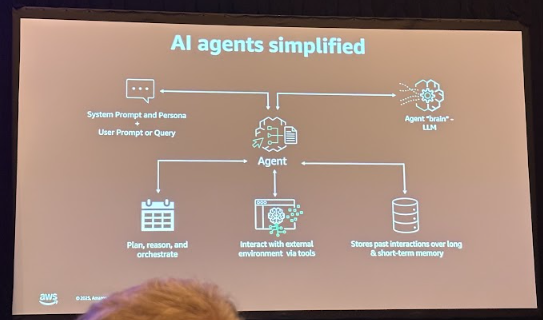
AWSが今回のセッションで強調していたのは、「AIエージェントはLLMだけでは成立せず、複数の機能が統合された構造を持つ」という点です。 ここでは、提示された図をもとにその全体像を確認します。
1. Reason(推論)※右上 「Agent brain - LLM」
LLMがユーザーの意図を理解し、必要な情報を推論します。
2. Plan(計画)※左下 「Plan, reason, and orchestrate」
推論結果をもとに、目的達成のためのステップを組み立てます。
3. Act(行動:ツール実行)※中央下 「Interact with external environment via tools」
APIやMCPサーバーなど外部ツールを呼び出し、実際に操作を行います。
エージェントが外の世界に作用する部分です。
4. Memory(短期・長期)※右下 「Stores past interactions」
会話の文脈(短期)やユーザー設定・嗜好(長期)を保持し、継続的な応答を可能にします。
5. Prompt / Persona(指示・役割)※左上 「System prompt and persona / User prompt」
エージェントの性格・役割・行動方針を定義する設定です。
AIエージェントを企業利用する際の課題
企業利用ではモデルの性能より運用の統制が問題になります。
- AIエージェントはどのデータに触れてよいか
- AIエージェントはどの操作を許可するか
- AIエージェントの監査証跡をどう残すか
- AIエージェントの誤動作をどう封じ込めるか
AWSはこの課題を解決するためにMCP(業界標準プロトコル)を採用し、AgentCoreを整備し、さらにエージェント開発プロセスを標準化するためにKiroを提供しています。 次の章では3つの要素について解説します。
要素① MCP:エージェントの行動範囲を標準化するオープンプロトコル
MCPは2024年に登場した業界標準です。OpenAIが「エージェントが外部システムと安全にやり取りするための新しい統一プロトコル」として発表しました。
MCPが定義するものは
- 許可された外部API
- JSON入出力の形式
- 実行可能な操作の宣言
- ログ・トレースの標準化
- セキュリティ境界
つまりMCPは、「エージェントが勝手な行動をしないようにするガードレールを、世界共通の仕様として提供する」という役割を担っています。
要素② Kiro:MCP準拠エージェントを量産するSpec-Driven開発フレームワーク
KiroはMCP準拠のエージェントおよびMCPサーバー構造を「仕様(Spec)」から自動生成するSpec-Driven Frameworkです。
- 開発者はまず仕様(Spec)を書く
- Kiroがエンドポイントや入出力形式、ハンドラ構造まで自動生成する
- これにより、外部システムとの安全な連携方法が標準化される
要素③ AgentCore:エージェント運用のためのOSになるマネージドランタイム
AgentCoreはMCP準拠のエージェントを本番環境で安全に実行するためのランタイムです。 ここでいうランタイムとは「単なる実行層」ではなく、エージェント運用に必要な基盤機能をOSのようにまとめて提供する実行環境を指します。 そのランタイムの内部には、企業運用で必ず必要になる次のコンポーネントが標準で組み込まれています。
- Identity(誰が操作しているか)
- Policy(何をしてよいか)
- ★Gateway(外部ツールとの接続)
- ★Memory(短期・長期)
- ★Observability(Logs / Traces / Metrics)
- Evaluations(テスト・性能評価)
※★については次の章でさらに掘り下げます。
講師が強調していたのは、この点です。
「これらは開発者が本来やりたくないが、エージェントシステムとしては必ず必要になる作業だ。だからAWSがランタイム側で吸収する。」
つまりAgentCoreは、エージェントが動く実行基盤(ランタイム)でありながら、運用に欠かせない重い部分をすべてマネージド化してくれる存在です。OSのように、エージェント運用に必要な共通機能をまとめて提供する基盤だと捉えられます。 これらの機能はIAM(権限制御)、Lambda(実行基盤)、CloudWatch(可観測性)と統合されることで実現しています。
Gateway:semantic searchを用いた最適なツール選択
エージェントは通常、数十〜数百のツール(API、Lambda、MCPサーバーなど)を利用できます。しかし、 どのツールを使うべきかをLLMに丸投げすると、迷う・誤る・無駄な呼び出しが増えるという問題が必ず発生します。 AgentCore Gatewayはこの問題を改善します。 Gatewayは外部ツールへの唯一の入口として、semantic searchで最適なツールを選びつつ、許可された操作だけを通すアクセス制御レイヤとして機能します。
これにより
- 誤ったツール選択の防止(セキュリティ事故の抑制)
- token使用量の削減(LLMに渡すコンテキストを極小化)
- レイテンシ改善(探す時間・呼び過ぎの防止)
といったメリットが生まれます。
Memory:短期・長期メモリの統合
エージェントの現在の状況と、これまでに蓄積した知識を整理して活用するための仕組みです。
- 短期メモリ(Session Memory)は直近の会話やタスク状態を保持
- 長期メモリ(Semantic / Preference / Summary / Custom)はユーザーの嗜好や過去の要約、知識を保持
重要なのは必要な記憶だけが自動で抽出され、LLMに渡されるという点。 これにより、エージェントは少ないトークンで文脈を維持しつつ、より一貫性のある応答ができる。
Observability:CloudWatchでエージェントを分解して見る
エージェント運用では、ブラックボックス化が最大のリスクです。 どのステップが遅いのか、どのツールを何回呼んだのか、どの処理がコストを押し上げているのか。 これを正しく把握するために、AgentCoreは以下のようなエージェントの動作をCloudWatch上で分解して観測できる仕組みを提供します。
- agent input / output
- tool calls
- latency
- tokens(input / output)
- MCPサーバーの呼び出しトレース
講師が強調していたのは、この点です。
「あなたはspan(ステップ)ごとにtokenとlatencyを分析すべきだ」
これはマルチエージェントが前提になる未来において極めて重要なポイント。AIエージェントは1回の処理の裏側で複数のステップ(推論→計画→ツール実行→メモリ検索...)を実行しています。 マルチエージェントではこの連鎖がさらに複雑化し、どのステップが遅延やコスト増の原因なのか、全体のログだけでは把握できません。
そのため「各ステップを分解し、token使用量とlatencyを可視化する」ことが、 コスト最適化・性能改善・誤作動検知のすべてにおいて必須になります。
まとめ
AI の価値の中心は、「モデル性能」から「エージェントをどう安全に・スケールして動かすか」へ移行しつつあります。
「Building AI Agents with Kiro, MCP, and Amazon Bedrock AgentCore (DEV331)」は、AWSが描く「企業向けAIエージェント基盤」の全体像を最も立体的に示したセッションでした。 MCP・Kiro・AgentCoreを単なる個別技術ではなく、一つのパイプラインとして理解できた点が最大の収穫です。
この記事は私が書きました
河野 桂子
記事一覧ヨシ!
