- 公開日
- 最終更新日
【Quick Suite】Quick Suiteでデータを可視化してみた
この記事を共有する

目次
はじめに
はじめまして。パーソル&サーバーワークスの村上です。
最近、Amazon Quick Suite(以下、Quick Suite)を用いてお客様にデータの可視化のデモを行ったので、その構築手順を備忘録として残します。
Quick Suiteに初めて触れる方の参考にしていただければと思います。
Quick Suiteとは
AWSのBIサービスであるAmazon QuickSightに生成AI機能を追加して、リブランディングされたBIサービスになります。
環境
OS: Amazon Linux 2023
Python: 3.12.5
構築手順
構築までの流れとしては、元データのCSVファイルをAmazon S3(以下、S3)に準備して、S3から期間や金額など任意の属性でデータをAmazon Athena(以下、Athena)で取得出来るように設定します。
Athenaのクエリで取得した結果をQuick Suiteのデータセットとして取り込むことで、Quick Suiteでデータの分析・可視化までを行っていきます。
①S3にデータを準備
②Athenaの設定
③Quick Suiteの設定
①S3にデータを準備
Amazon Linux 2023にてS3のデータ準備を行っています。
まずは、作業用のディレクトリを作成します。
mkdir -p /home/ec2-user/Local/quick-sight/test
テストデータの作成
今回は、商品の売上推移などを可視化することを想定して以下のような構造でデモ用のCSVファイルを作成していきます。
transactionsディレクトリ配下では各月ごとに商品取引情報を管理して、masterディレクトリ配下では顧客・部署・商品・社員情報を管理しています。
├── transactions # 2023年1月から2025年12月までの各月の取引情報
│ ├── year=2023
│ │ ├── month=01
│ │ │ └── transactions.csv
.
│ ├── year=2025
│ │ ├── month=01
│ │ │ └── transactions.csv
.
│ └── month=12
│ └── transactions.csv
├── master
├── customers
│ └── customers.csv # 顧客テーブル情報
├── departments
│ └── departments.csv # 部署テーブル情報
├── products
│ └── products.csv # 商品テーブル情報
└── staff
└── staff.csv # 社員テーブル情報
以下データ生成スクリプトで、デモ用データを準備していきます。
generate_transactions.py
import csv
import random
from datetime import datetime, timedelta
import os
# マスターデータの範囲
PRODUCTS = [f'P{i:03d}' for i in range(1, 21)] # P001-P020
CUSTOMERS = [f'C{i:03d}' for i in range(1, 21)] # C001-C020
DEPARTMENTS = [f'D{i:03d}' for i in range(1, 11)] # D001-D010
STAFF = [f'S{i:03d}' for i in range(1, 51)] # S001-S050
# 商品ごとの価格帯を設定
PRODUCT_PRICES = {
'P001': (80000, 150000),
'P002': (60000, 120000),
'P003': (30000, 80000),
'P004': (50000, 120000),
'P005': (20000, 35000),
'P006': (30000, 50000),
'P007': (3000, 15000),
'P008': (1000, 8000),
'P009': (30000, 60000),
'P010': (50000, 150000),
}
def generate_transaction_id(year, month, seq):
"""帳票IDを生成: T + 年月 + 連番"""
return f'T{year}{month:02d}{seq:03d}'
def generate_transactions_for_month(year, month, rows_per_month=10):
"""指定された年月の帳票データを生成"""
transactions = []
# その月の日数を取得
if month == 12:
next_month = datetime(year + 1, 1, 1)
else:
next_month = datetime(year, month + 1, 1)
days_in_month = (next_month - datetime(year, month, 1)).days
for seq in range(1, rows_per_month + 1):
# 商品を選択
product_id = random.choice(PRODUCTS)
# 商品に応じた価格帯から金額を決定
min_price, max_price = PRODUCT_PRICES[product_id]
unit_price = random.randint(min_price // 1000, max_price // 1000) * 1000
# 数量(1-10個)
quantity = random.randint(1, 10)
# 金額 = 単価 × 数量
amount = unit_price * quantity
# その月のランダムな日付
day = random.randint(1, days_in_month)
invoice_date = f'{year}-{month:02d}-{day:02d}'
transaction = {
'transaction_id': generate_transaction_id(year, month, seq),
'product_id': product_id,
'quantity': quantity,
'customer_id': random.choice(CUSTOMERS),
'department_id': random.choice(DEPARTMENTS),
'staff_id': random.choice(STAFF),
'issue_date': invoice_date
}
transactions.append(transaction)
return transactions
def main():
# 出力ディレクトリの作成
base_dir = 'transactions'
# 2023年1月から2025年12月までのデータを生成
for year in range(2023, 2026):
for month in range(1, 13):
# フォルダ構造: transactions/year=YYYY/month=MM/
year_dir = os.path.join(base_dir, f'year={year}')
month_dir = os.path.join(year_dir, f'month={month:02d}')
# ディレクトリを作成
os.makedirs(month_dir, exist_ok=True)
# その月の帳票データを生成
transactions = generate_transactions_for_month(year, month, rows_per_month=10)
# CSVファイルに出力
csv_file = os.path.join(month_dir, 'transactions.csv')
with open(csv_file, 'w', encoding='utf-8', newline='') as f:
fieldnames = ['transaction_id', 'product_id', 'quantity', 'customer_id', 'department_id', 'staff_id', 'issue_date']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(transactions)
print(f'Created: {csv_file} ({len(transactions)} rows)')
print(f'\n合計: {3 * 12 * 10} = 360行のデータを生成しました')
if __name__ == '__main__':
main()
generate_master.py
import os
import csv
import random
BASE_DIR = "master"
# -------------------------
# サンプルデータ候補
# -------------------------
COMPANY_PREFIX = [
"株式会社", "有限会社"
]
COMPANY_NAMES = [
"山田商事", "佐藤物産", "鈴木製作所", "高橋電機",
"田中食品", "伊藤運輸", "中村工業", "小林企画",
"加藤システムズ", "吉田商会", "山本建設", "松本印刷",
"井上商店", "木村電気", "林コーポレーション",
"清水サービス", "斎藤不動産", "森テック",
"阿部物流", "池田化学"
]
LAST_NAMES = [
"山田", "佐藤", "鈴木", "高橋", "田中",
"伊藤", "中村", "小林", "加藤", "吉田",
"山本", "松本", "井上", "木村", "林",
"清水", "斎藤", "森", "阿部", "池田"
]
FIRST_NAMES = [
"太郎", "一郎", "健一", "大輔", "翔太",
"直樹", "亮", "誠", "裕介", "和也",
"美咲", "由美", "彩香", "愛", "真由",
"奈々", "恵", "明日香", "優子", "陽菜"
]
DEPARTMENTS = [
"営業第一部", "営業第二部", "企画部", "総務部",
"人事部", "経理部", "情報システム部",
"開発部", "品質管理部", "物流部"
]
PRODUCTS = [
"ノートPC", "デスクトップPC", "タブレット端末", "スマートフォン",
"モニター", "キーボード", "マウス", "プリンター",
"ルーター", "外付けHDD"
]
# -------------------------
# ディレクトリ作成
# -------------------------
def ensure_dirs():
for d in ["customers", "departments", "products", "staff"]:
os.makedirs(os.path.join(BASE_DIR, d), exist_ok=True)
# -------------------------
# CSV作成処理
# -------------------------
def create_customers():
path = os.path.join(BASE_DIR, "customers", "customers.csv")
with open(path, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["customer_id", "customer_name"])
for i in range(1, 21):
company = f"{random.choice(COMPANY_PREFIX)}{COMPANY_NAMES[i-1]}"
writer.writerow([f"C{i:03d}", company])
def create_departments():
path = os.path.join(BASE_DIR, "departments", "departments.csv")
with open(path, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["department_id", "department_name"])
for i, dept in enumerate(DEPARTMENTS, start=1):
writer.writerow([f"D{i:03d}", dept])
def create_products():
path = os.path.join(BASE_DIR, "products", "products.csv")
with open(path, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["product_id", "product_name", "price"])
for i, product in enumerate(PRODUCTS, start=1):
price = random.randint(50000, 150000)
writer.writerow([f"P{i:03d}", product, price])
def create_staff():
path = os.path.join(BASE_DIR, "staff", "staff.csv")
with open(path, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["staff_id", "staff_name"])
for i in range(1, 31):
name = f"{random.choice(LAST_NAMES)}{random.choice(FIRST_NAMES)}"
writer.writerow([f"S{i:03d}", name])
# -------------------------
# メイン処理
# -------------------------
def main():
ensure_dirs()
create_customers()
create_departments()
create_products()
create_staff()
print("masterデータを生成しました")
if __name__ == "__main__":
main()
デモ用データ生成スクリプトを実行していきます。
$ python generate_transactions.py
# Created: transactions/year=2023/month=01/transactions.csv (10 rows)
# Created: transactions/year=2023/month=02/transactions.csv (10 rows)
# .
# Created: transactions/year=2025/month=12/transactions.csv (10 rows)
# 合計: 360 = 360行のデータを生成しました
$ python generate_master.py
# masterデータを生成しました
スクリプト実行後、取引データとマスタテーブルのcsvが以下のように作成されます。
$ tree.
├── transactions # 2023年1月から2025年12月までの各月の取引情報
│ ├── year=2023
│ │ ├── month=01
│ │ │ └── transactions.csv
.
│ ├── year=2025
│ │ ├── month=01
│ │ │ └── transactions.csv
.
│ └── month=12
│ └── transactions.csv
├── master
├── customers
│ └── customers.csv # 取引先テーブル情報
├── departments
│ └── departments.csv # 部署テーブル情報
├── products
│ └── products.csv # 商品テーブル情報
└── staff
└── staff.csv # 社員テーブル情報
続いて、生成されたデモ用のCSVファイルをS3バケットにアップロードします。
uploadtos3.sh
#!/bin/bash
# ===============================
# 設定
# ===============================
BUCKET_NAME="quicksight-demo-202601"
REGION="ap-northeast-1"
echo "======================================"
echo "S3へのデータアップロードを開始します"
echo "バケット名: ${BUCKET_NAME}"
echo "======================================"
# ===============================
# 0. S3バケット存在確認・作成
# ===============================
echo ""
echo "[0/2] S3バケットの存在確認中..."
if aws s3api head-bucket --bucket "${BUCKET_NAME}" 2>/dev/null; then
echo "✓ S3バケットは既に存在します"
else
echo "S3バケットが存在しないため作成します..."
aws s3api create-bucket \
--bucket "${BUCKET_NAME}" \
--region "${REGION}" \
--create-bucket-configuration LocationConstraint="${REGION}"
if [ $? -ne 0 ]; then
echo "✗ S3バケットの作成に失敗しました"
exit 1
fi
echo "✓ S3バケットを作成しました"
fi
# ===============================
# 1. マスターデータのアップロード
# ===============================
echo ""
echo "[1/2] マスターデータをアップロード中..."
# 商品データ
echo " - products.csv をアップロード中..."
aws s3 cp master/products/products.csv "s3://${BUCKET_NAME}/master/products/products.csv"
# 顧客データ
echo " - customers.csv をアップロード中..."
aws s3 cp master/customers/customers.csv "s3://${BUCKET_NAME}/master/customers/customers.csv"
# 部署データ
echo " - departments.csv をアップロード中..."
aws s3 cp master/departments/departments.csv "s3://${BUCKET_NAME}/master/departments/departments.csv"
# 担当者データ
echo " - staff.csv をアップロード中..."
aws s3 cp master/staff/staff.csv "s3://${BUCKET_NAME}/master/staff/staff.csv"
echo "✓ マスターデータのアップロード完了"
# ===============================
# 2. トランザクションデータのアップロード
# ===============================
echo ""
echo "[2/2] トランザクションデータをアップロード中..."
aws s3 sync transactions/ "s3://${BUCKET_NAME}/transactions/" --exclude "*.DS_Store"
echo "✓ トランザクションデータのアップロード完了"
# ===============================
# 3. アップロード結果の確認
# ===============================
echo ""
echo "======================================"
echo "アップロード完了!"
echo "======================================"
echo ""
echo "S3バケットの内容を確認:"
echo ""
echo "--- マスターデータ ---"
aws s3 ls "s3://${BUCKET_NAME}/master/" --recursive
echo ""
echo "--- トランザクションデータ (サンプル) ---"
aws s3 ls "s3://${BUCKET_NAME}/transactions/year=2024/month=01/"
echo ""
echo "すべてのパーティション:"
aws s3 ls "s3://${BUCKET_NAME}/transactions/" --recursive | grep "year=" | wc -l
echo "個のトランザクションファイルがアップロードされました"
以下のように、masterディレクトリとtransactionsディレクトリ配下にCSVデータがアップロードされていれば、データの準備は完了です。
sh upload_to_s3.sh
# ======================================
# アップロード完了!
# ======================================
#
# S3バケットの内容を確認:
#
# --- マスターデータ ---
# 2026-01-02 03:58:02 683 master/customers/customers.csv
# 2026-01-02 03:58:03 221 master/departments/departments.csv
# 2026-01-02 03:58:01 318 master/products/products.csv
# 2026-01-02 03:58:04 576 master/staff/staff.csv
#
# --- トランザクションデータ (サンプル) ---
# 2026-01-02 03:58:04 534 transactions.csv
#
# すべてのパーティション:
# 36
# 個のトランザクションファイルがアップロードされました
②Athenaの設定
続いて、Athenaで先ほどアップロードしたCSVファイルに対してSQLクエリを実行して、Viewテーブルを作成していきます。
データベースの作成
Athenaコンソールの「クエリエディタ」にて以下クエリを実行します。
クエリ実行後、添付画像のように「データ」>「データベース」に「quicksuite_demo」データベースが作成されていることを確認します。
CREATE DATABASE IF NOT EXISTS quicksuite_demo;
各テーブルの作成
各マスタテーブルを作成するためのクエリを実行していきます。
顧客テーブル
CREATE EXTERNAL TABLE IF NOT EXISTS quicksuite_demo.customers (
customer_id string,
customer_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://quicksuite-demo-202601/master/customers/'
TBLPROPERTIES ('skip.header.line.count'='1');
部署テーブル
CREATE EXTERNAL TABLE IF NOT EXISTS quicksuite_demo.departments (
department_id string,
department_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://quicksuite-demo-202601/master/departments/'
TBLPROPERTIES ('skip.header.line.count'='1');
商品テーブル
CREATE EXTERNAL TABLE IF NOT EXISTS quicksuite_demo.products (
product_id string,
product_name string,
price int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://quicksuite-demo-202601/master/products/'
TBLPROPERTIES ('skip.header.line.count'='1');
担当者テーブル
CREATE EXTERNAL TABLE IF NOT EXISTS quicksuite_demo.staff (
staff_id string,
staff_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://quicksuite-demo-202601/master/staff/'
TBLPROPERTIES ('skip.header.line.count'='1');
取引テーブル作成
CREATE EXTERNAL TABLE IF NOT EXISTS quicksuite_demo.transactions (
transaction_id string,
product_id string,
quantity int,
customer_id string,
department_id string,
staff_id string,
issue_date date
)
PARTITIONED BY (
year int,
month int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://quicksuite-demo-202601/transactions/'
TBLPROPERTIES ('skip.header.line.count'='1');
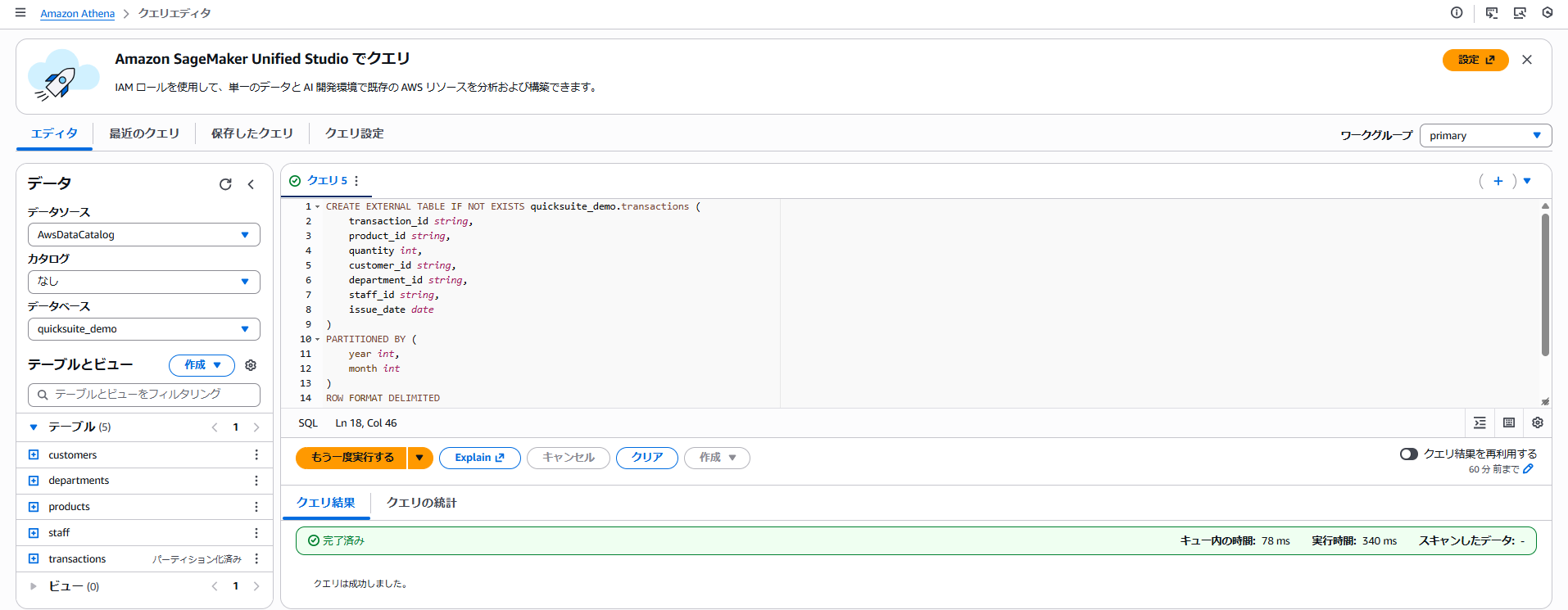
以下のように「テーブルとビュー」>「テーブル」で、5つのテーブルが作成されていることを確認します。
パーティションの追加
以下クエリで、作成されたパーティションの追加を行い、Athenaクエリのスキャンの効率化を図ります。
MSCK REPAIR TABLE quicksuite_demo.transactions;
Viewテーブルの作成
5つのテーブルをジョインして、QuickSuiteのデータセットとして利用出来るようにクエリを実行します。
CREATE OR REPLACE VIEW quicksuite_demo.v_transaction_details AS
SELECT
-- トランザクション情報
t.transaction_id,
t.issue_date,
t.year,
t.month,
-- 商品情報
t.product_id,
p.product_name,
p.price as product_price,
-- 数量・金額
t.quantity,
CAST(p.price as BIGINT) * t.quantity as total_amount, -- 計算列: 合計金額
-- 顧客情報
t.customer_id,
c.customer_name,
-- 部署情報
t.department_id,
d.department_name,
-- 担当者情報
t.staff_id,
s.staff_name
FROM quicksight_demo.transactions t
LEFT JOIN quicksight_demo.products p
ON t.product_id = p.product_id
LEFT JOIN quicksight_demo.customers c
ON t.customer_id = c.customer_id
LEFT JOIN quicksight_demo.departments d
ON t.department_id = d.department_id
LEFT JOIN quicksight_demo.staff s
ON t.staff_id = s.staff_id
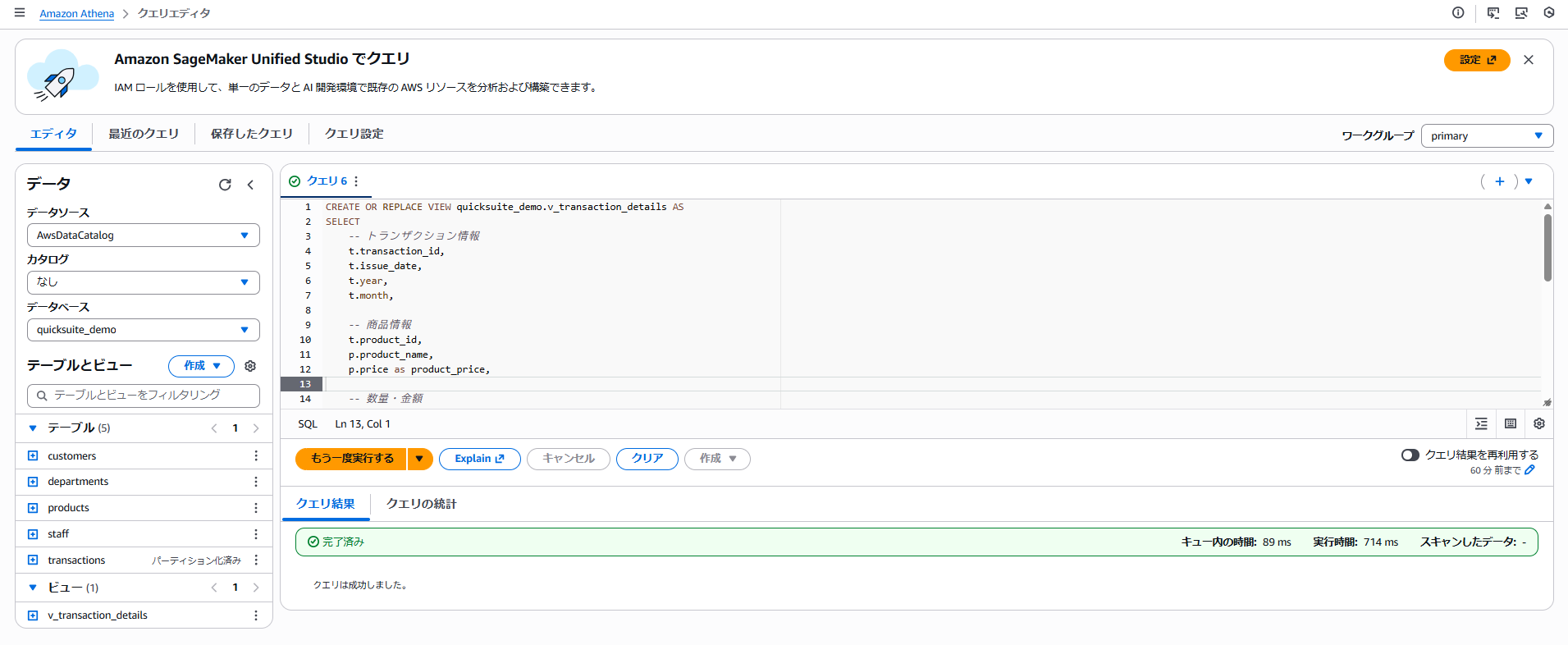
以下のように「テーブルとビュー」>「ビュー」で、「v_transaction_details」が作成されていれば、Athenaの設定は完了です。
③Quick Suiteの設定
データセットの設定
続いて、Quick Suiteで分析用のデータセットを作成します。
Quick Suiteコンソール画面の「データセット」>「データセットを作成」>「データソースを作成」をクリックして、「Amazon Athena」を選択後、「次へ」をクリックします。
データソースの作成画面にて、以下値を設定して「データソースを作成」をクリックします。
- データソース名:「quicksuitedemo-athena-database」
- Athenaワークグループ:[ primary ]
データソース作成後に、テーブルの選択で以下値を設定して「選択」をクリックします。
- カタログ:AwsDataCatalog
- データベース:「quicksuite_demo」
- テーブル:「v_transaction_details」
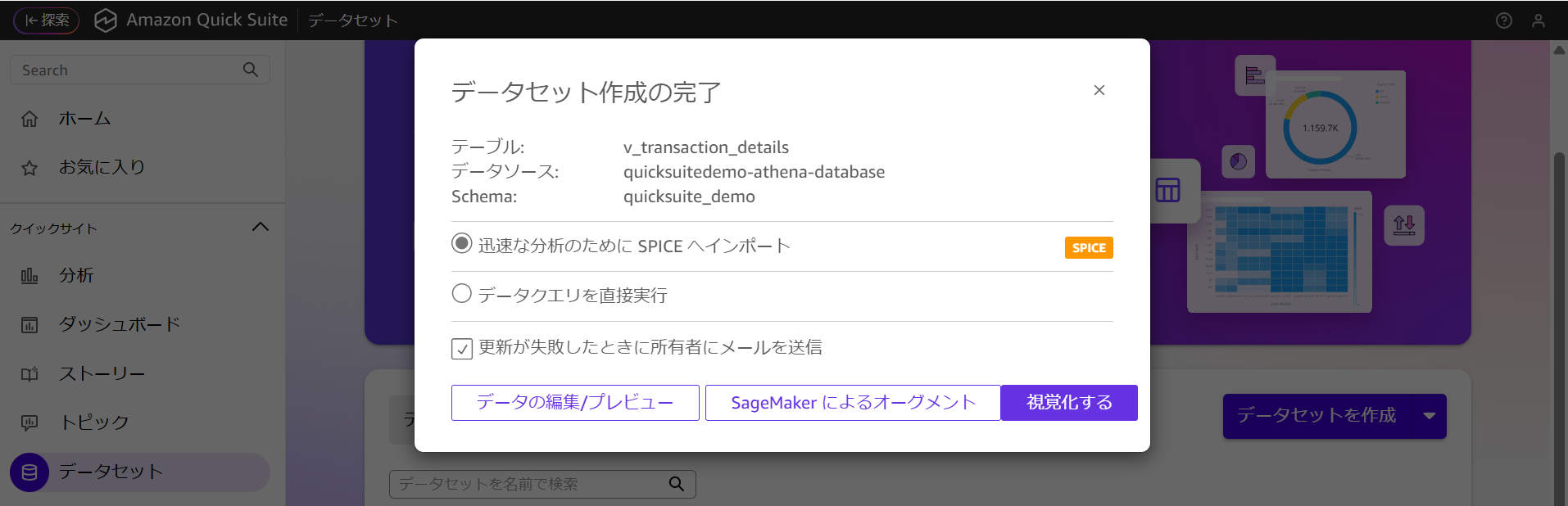 画像のようにデータセット作成が完了していることを確認します。
画像のようにデータセット作成が完了していることを確認します。
作成後のデータセットに対して分析・可視化を行うため「迅速な分析のためにSPICEへインポート」を選択して、「視覚化」をクリックします。
分析・可視化
作成済みのデータセットに対して分析・可視化を行っていきます。
Quick Suiteコンソール画面の「分析」から対象のシートに以下値を設定してグラフを作成します。
- データセット:「v_transaction_details」
- ビジュアル:「円グラフ」
- グループ/色:「product_name」
- 値:「total_amount(合計)」
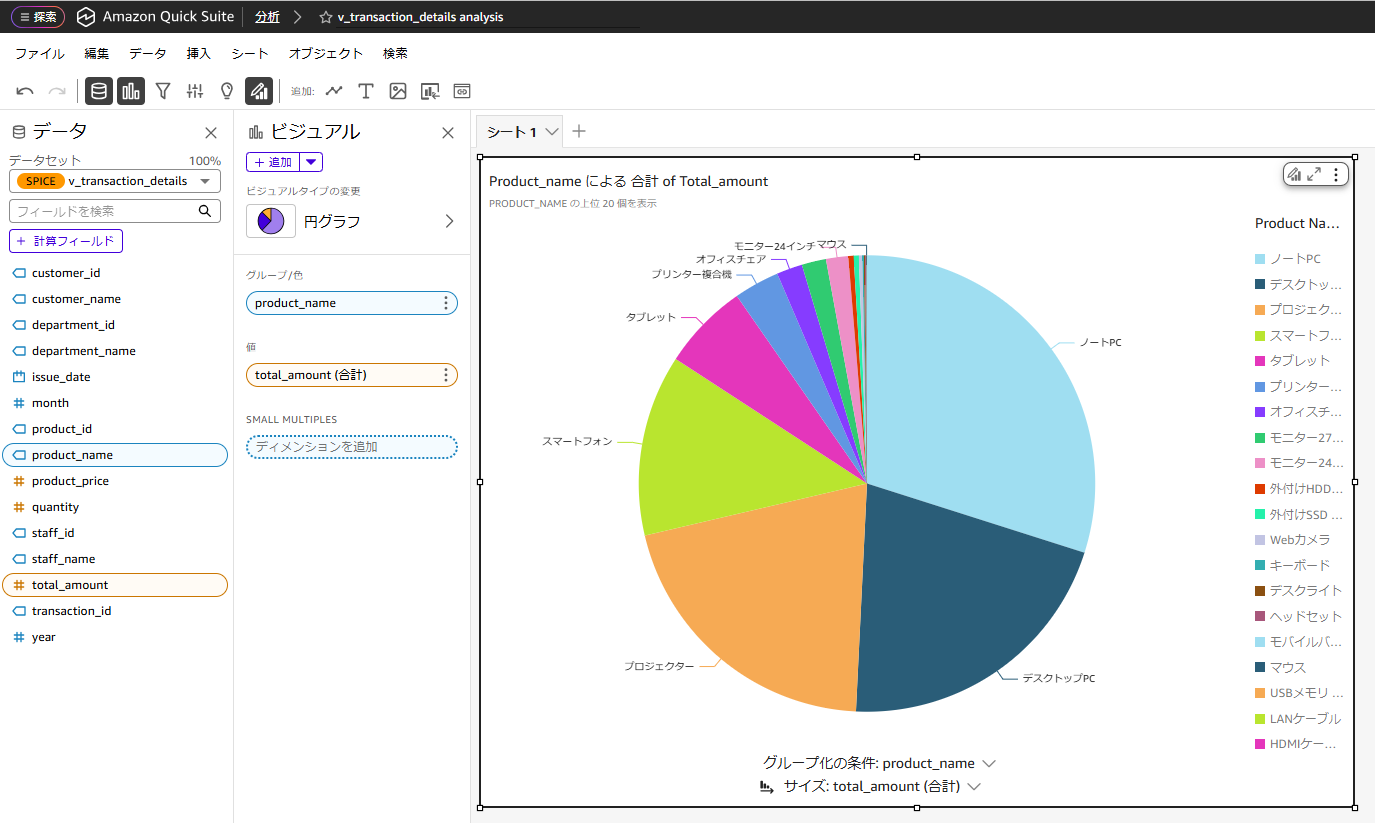 画像のように売上全体に対する各商品の比率を円グラフで表示することが出来ました。
画像のように売上全体に対する各商品の比率を円グラフで表示することが出来ました。
まとめ
今回、Quick SuiteでUI上でフィールド名をドラッグするだけで直感的に、グラフやテーブルを作成することが出来ました。
また、Athenaを使ってデータセットを作成してみましたが、AWSサービスはもちろん、GithubやDatabricksなどのサードパーティサービスとも連携が可能なため、データ量など異なるユースケースで別のデータウェアハウスサービスを利用する際でもQuick SuiteでBI機能については一元的に管理が出来そうです。
すぐにQuick Suiteでデモをしてみたい方に本記事がご参考になれば幸いです。
この記事は私が書きました
村上 大地
記事一覧筋トレとサウナの合間にDevOpsを学んでいます。
