- 公開日
- 最終更新日
【Lambda】ExcelファイルをLambda関数で処理してみた
この記事を共有する

目次
サービスG松原です。今回はExcelファイルをAWS Lambda(以下、Lambda)で処理してみたいな~と思い試してみました。
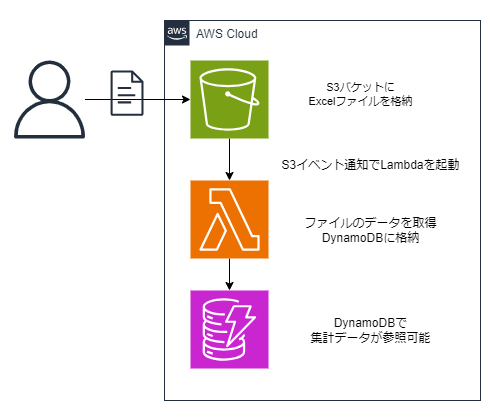
やりたいこと/構成図
構成はこんな感じです。
- ExcelファイルをAmazon S3(以下、S3)に格納し、S3イベント通知でLambdaを起動
- Lambdaでデータを処理してDynamoDBにデータ格納
今回取り込むExcelファイルのフォーマットは以下です。 ここから品目と個数、売上合計を取得していきます。
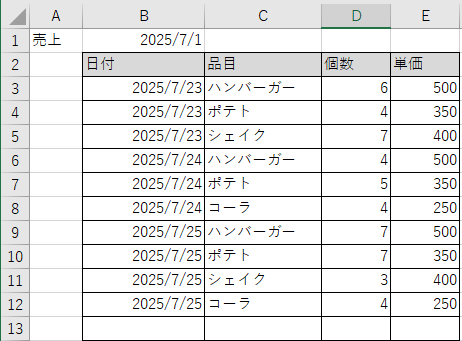
(なんとなくの売上表概念のようなもの)
実施手順
実施手順を記載します。
外部ライブラリ用ファイル作成
AWSマネジメントコンソールでCloudShellを開き、外部ライブラリのzipを作成します。(pandasとopenpyxlを取得)
mkdir -p python/lib/python3.9/site-packages
pip install pandas openpyxl -t python/lib/python3.9/site-packages
zip -r ./layer.zip ./python
※手頃なLinux環境ということでCloudShellを使いましたがなんでもよいです。 CloudShell環境がPython3.9なので以降python3.9環境で構築していきます。
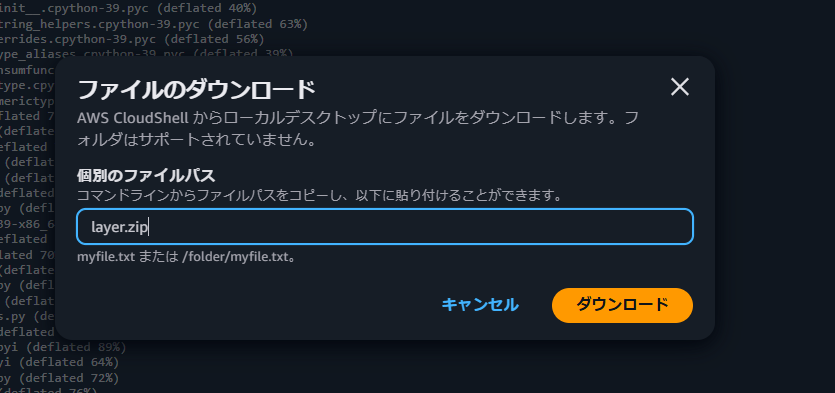
ライブラリ用ファイルをCloudShellからローカルにダウンロードします。
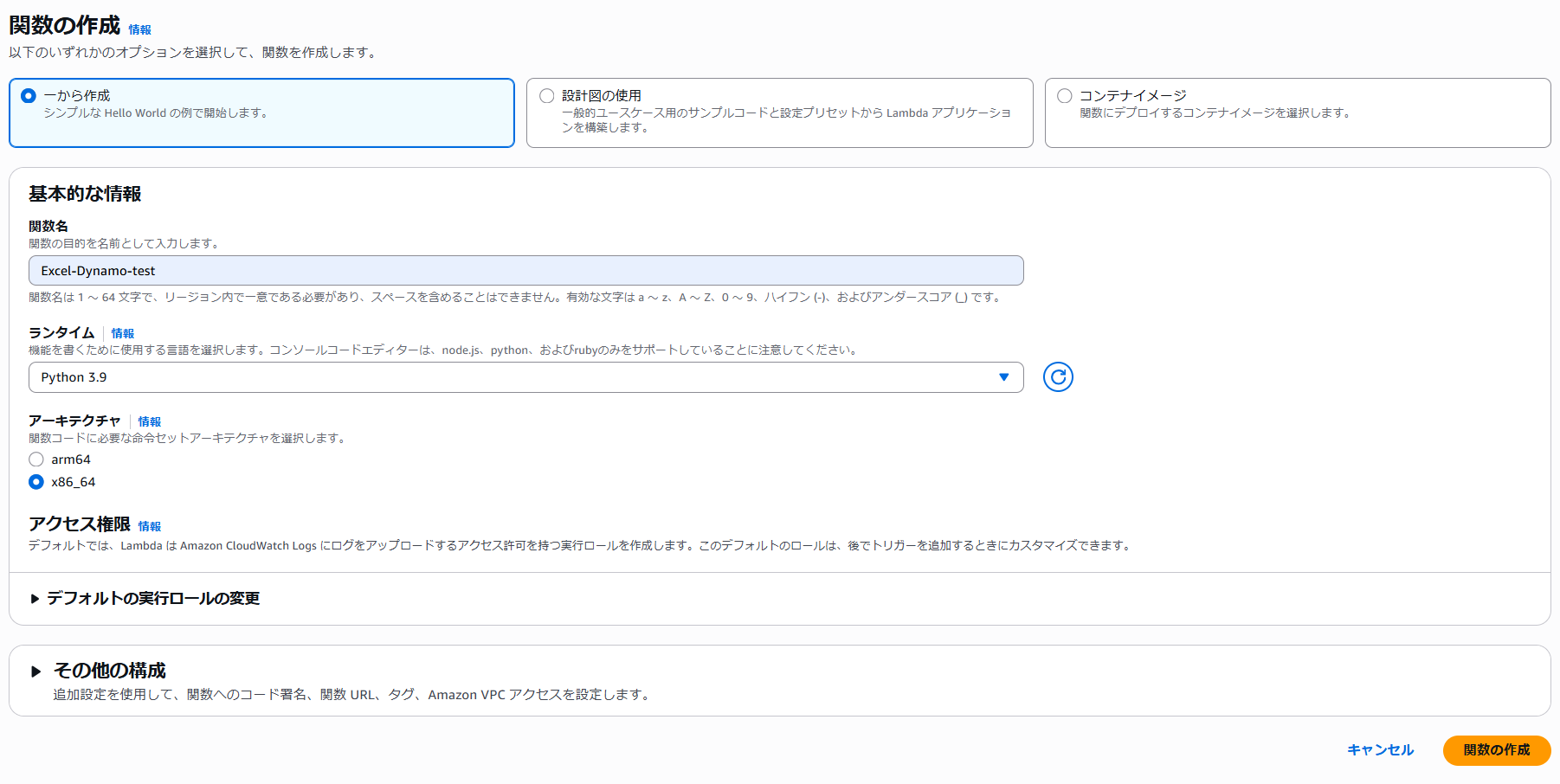
Lambda関数の作成
Lambda関数を作成します。ランタイムはPython3.9で作成します。
Lambda関数作成後、設定 > 一般設定からタイムアウト時間をデフォルトの3秒から5分に変更します。(デフォルト値だとタイムアウトするため)
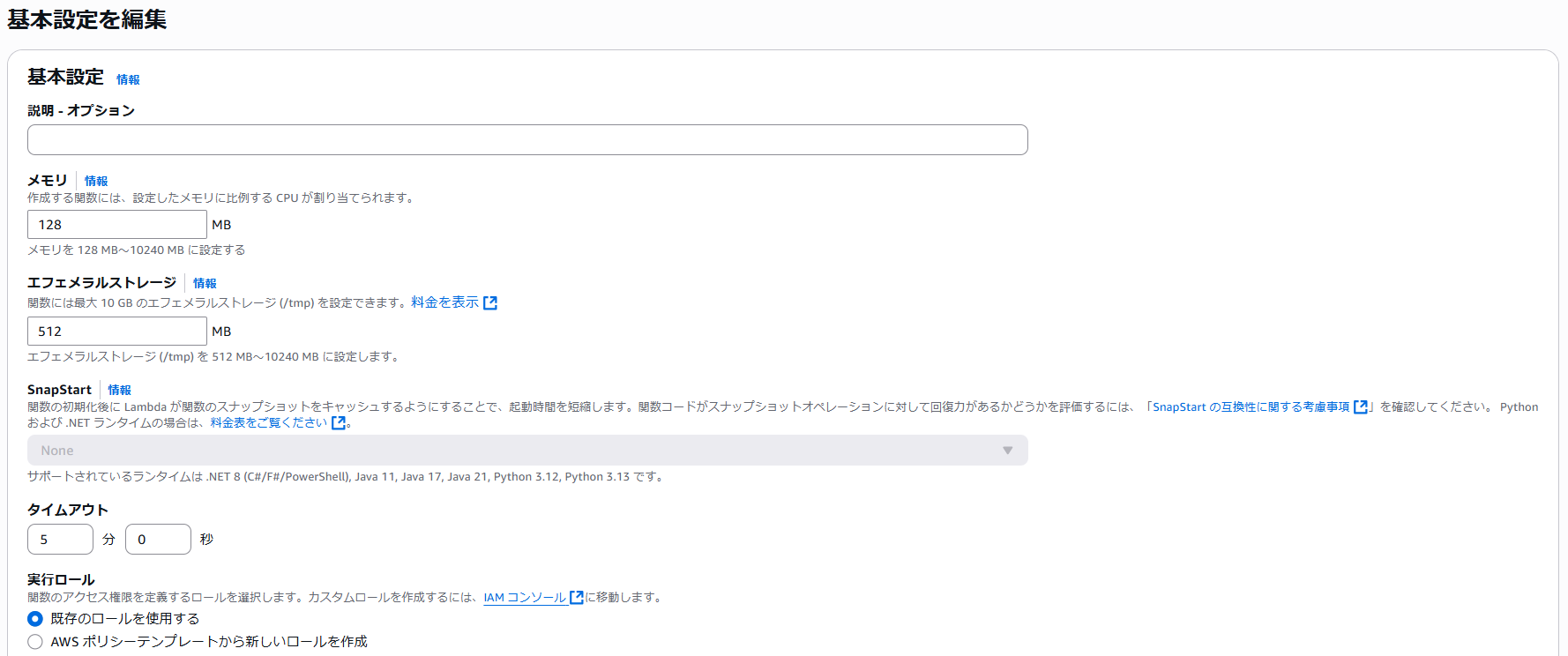
Lambdaレイヤーの作成
外部ライブラリを配置するためのLambdaレイヤーを作成します。
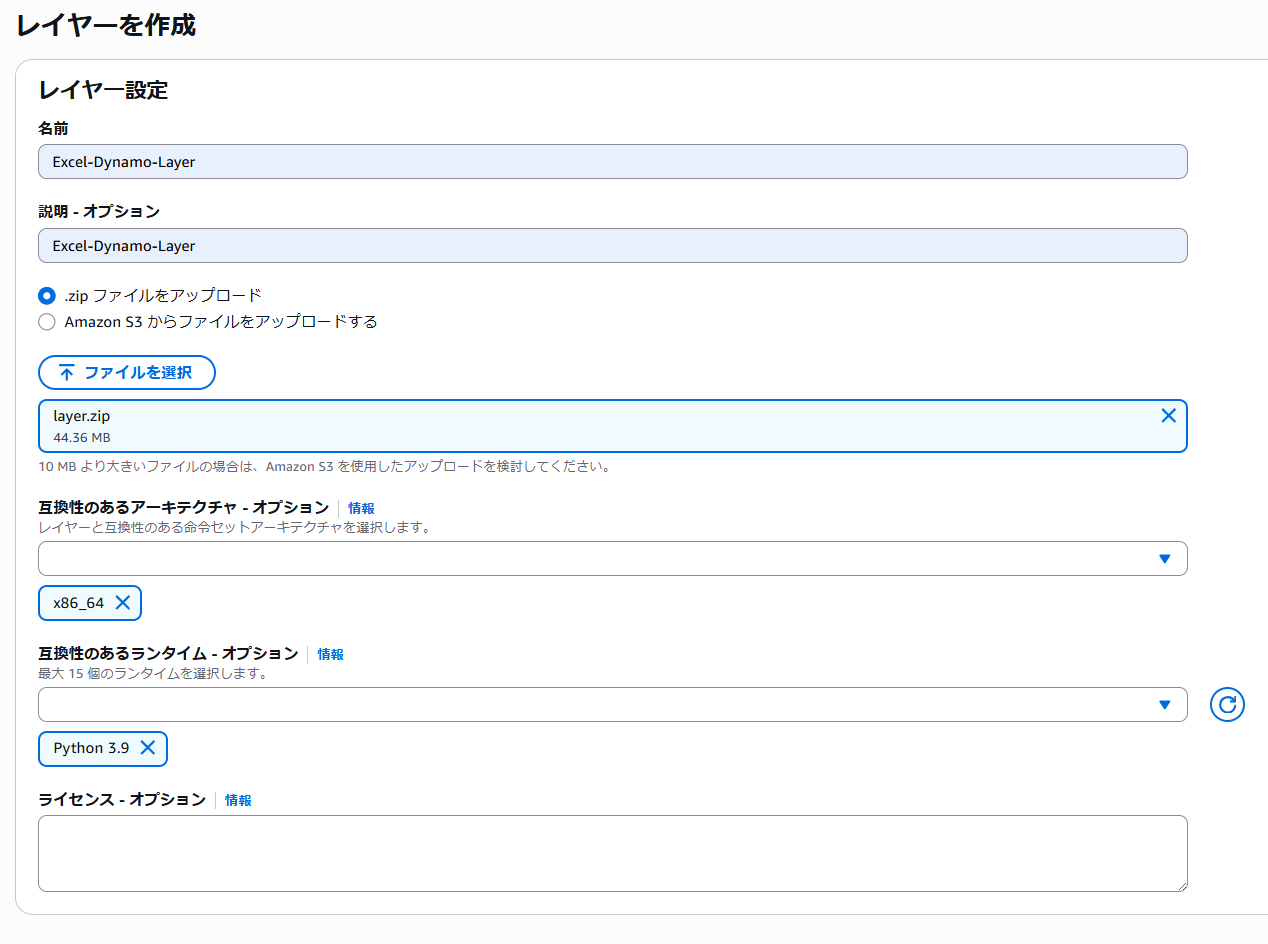
Lambda > レイヤー > レイヤーの作成を選択
「.zipファイルをアップロード」で前手順で取得したlayer.zipを選択し、アーキテクチャはx86_64、互換性のあるランタイムはPython3.9を選択します。
Lambda関数にLambdaレイヤーを設定
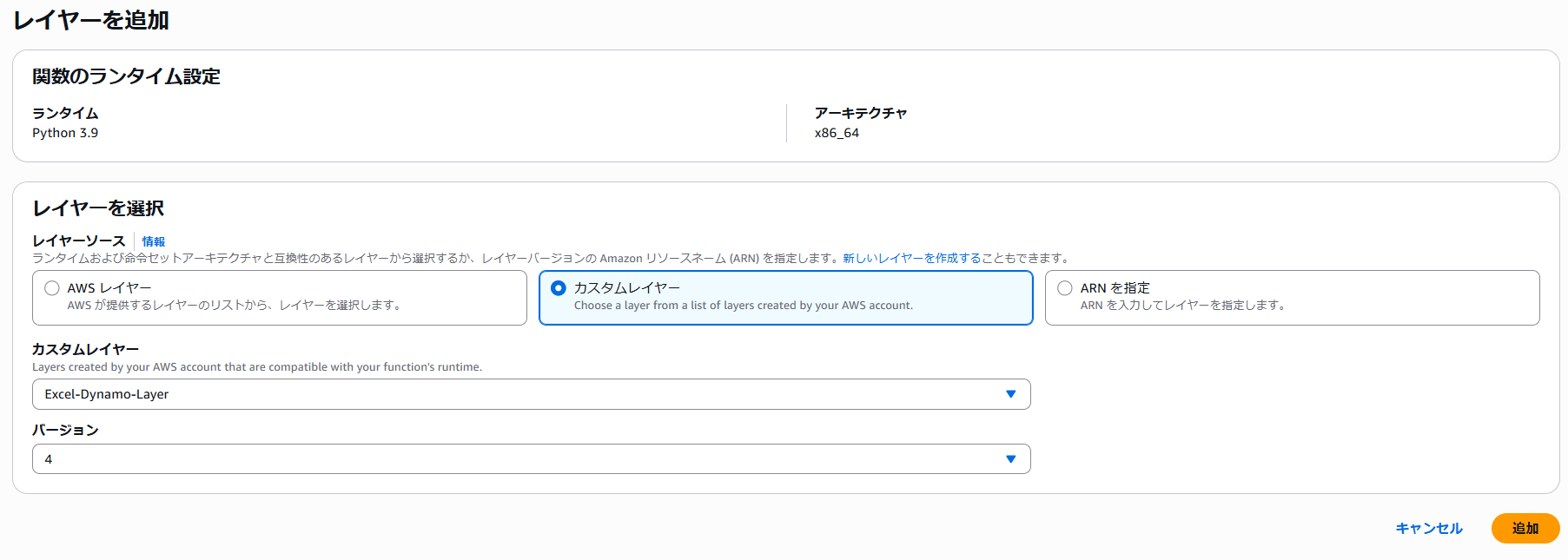
Lambdaのコードタブ下部の「レイヤー」で前段で作成したレイヤーを設定します。
Lambda関数 >「コード」タブ下部「レイヤー」>「レイヤーの追加」を選択
カスタムレイヤー > 前手順で作成したレイヤーを選択します。
Lambda関数のコード修正
Lambda関数をデフォルトから修正します。コードソースを以下に変更/保存し、Deployを押下して反映させます。
import pandas as pd
import boto3
import tempfile
import urllib.parse
s3 = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('SalesSummary')
def lambda_handler(event, context):
try:
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
print(f"bucket={bucket}, key={key}")
with tempfile.NamedTemporaryFile() as tmp:
s3.download_file(bucket, key, tmp.name)
df = pd.read_excel(tmp.name, header=1, usecols="B:E")
df.columns = ['date', 'item', 'count', 'unit_price']
df['date'] = pd.to_datetime(df['date'], errors='coerce')
df['item'] = df['item'].astype(str)
df['count'] = pd.to_numeric(df['count'], errors='coerce').fillna(0).astype(int)
df['unit_price'] = pd.to_numeric(df['unit_price'], errors='coerce').fillna(0).astype(int)
df = df.dropna(subset=['date', 'item'])
df['amount'] = df['count'] * df['unit_price']
grouped = df.groupby(['date', 'item'], as_index=False).agg(
total_count=('count', 'sum'),
total_amount=('amount', 'sum')
)
print(grouped)
for _, row in grouped.iterrows():
item = {
'date': str(row['date'].date()),
'item': row['item'],
'total_count': int(row['total_count']),
'total_amount': int(row['total_amount'])
}
print(f'Put item: {item}')
table.put_item(Item=item)
return {'status': 'ok', 'count': len(grouped)}
except Exception as e:
print(f"Error: {e}")
raise
コードについて補足:Excelファイル名に日本語が含まれる場合、urllib.parse.unquote_plusでデコードが必要です。(動作検証時にこれでちょっと沼りました)
DynamoDBのテーブル作成
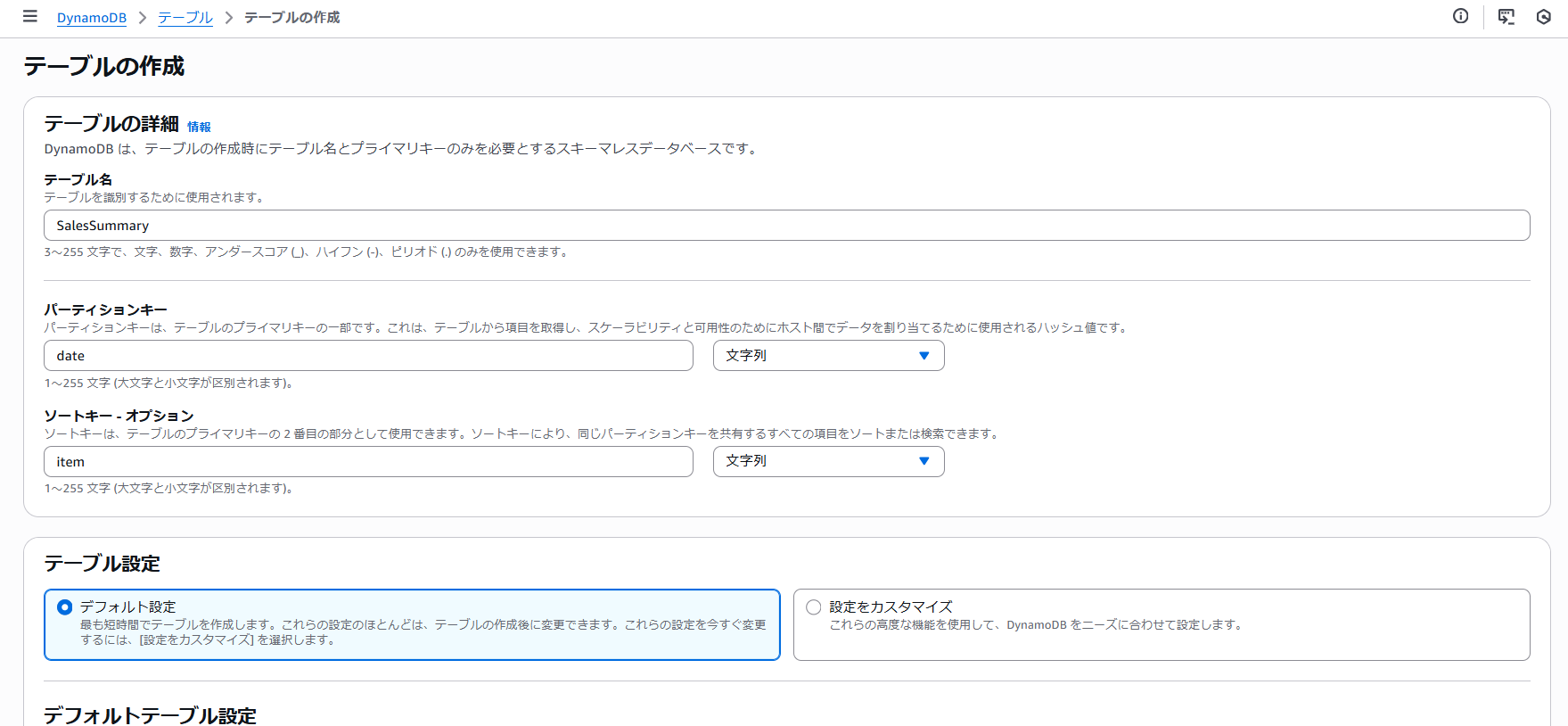
続いてデータの格納先のDynamoDBテーブルを作成します。
DynamoDB > テーブルを作成
- テーブル名: SalesSummary
- パーティションキー: date(型:文字列)
- ソートキー: item(型:文字列)
- その他のオプションはデフォルト
S3バケットの作成
Excelファイルを格納するS3バケットを作成します。
任意の名前でS3バケットを作成し、バケット配下にsalesdataフォルダを作成します。
S3イベント通知の設定
S3にファイルアップロードされたイベントからLambda関数を起動するS3イベント通知を設定します。
S3バケット > プロパティ > イベント通知 > イベント通知を作成
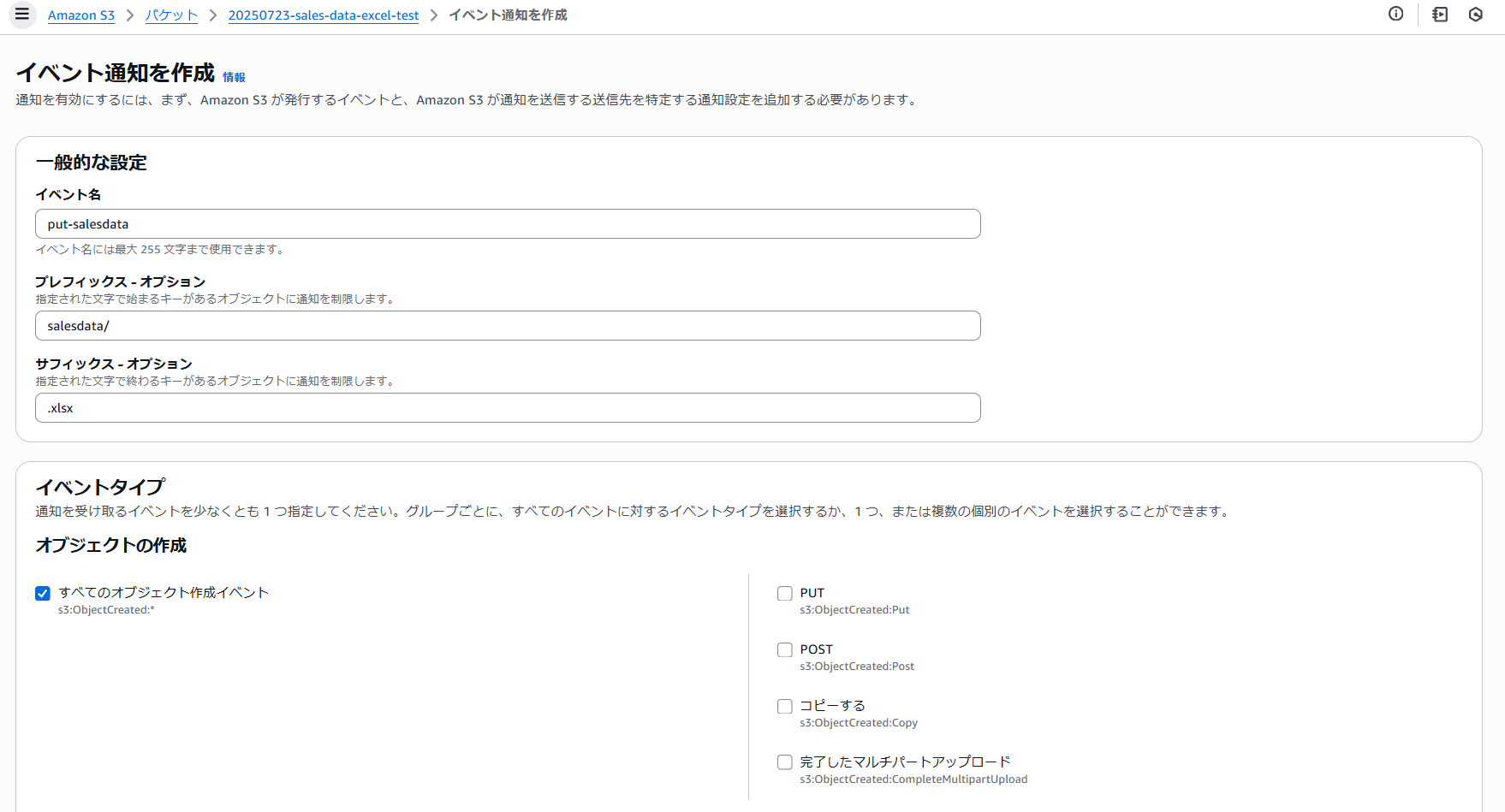
以下の設定で作成します。
- プレフィックス: salesdata/
- サフィックス: .xlsx
- イベントタイプ:すべてのオブジェクト作成イベント
- 送信先:Lambda関数 ※前手順で作成したLambda関数を指定
Lambda実行ロールへの権限追加
Lambda関数の実行ロールに権限を追加します。
今回はS3バケットからのファイル取得とDynamoDBへの書き込み権限を追加します。
- 以下のIAMポリシーを作成し、Lambda実行ロールにアタッチする
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": "arn:aws:s3:::対象のS3バケット/*"
},
{
"Effect": "Allow",
"Action": [
"dynamodb:PutItem"
],
"Resource": "arn:aws:dynamodb:ap-northeast-1:アカウントID:table/SalesSummary"
}
]
}
上記でリソースの作成/設定は完了です。
動作確認
作成リソースの動作確認は以下の方法で実施しました。
- S3バケットの「salesdata」フォルダ配下に指定フォーマットのExcelファイルをアップロードします。
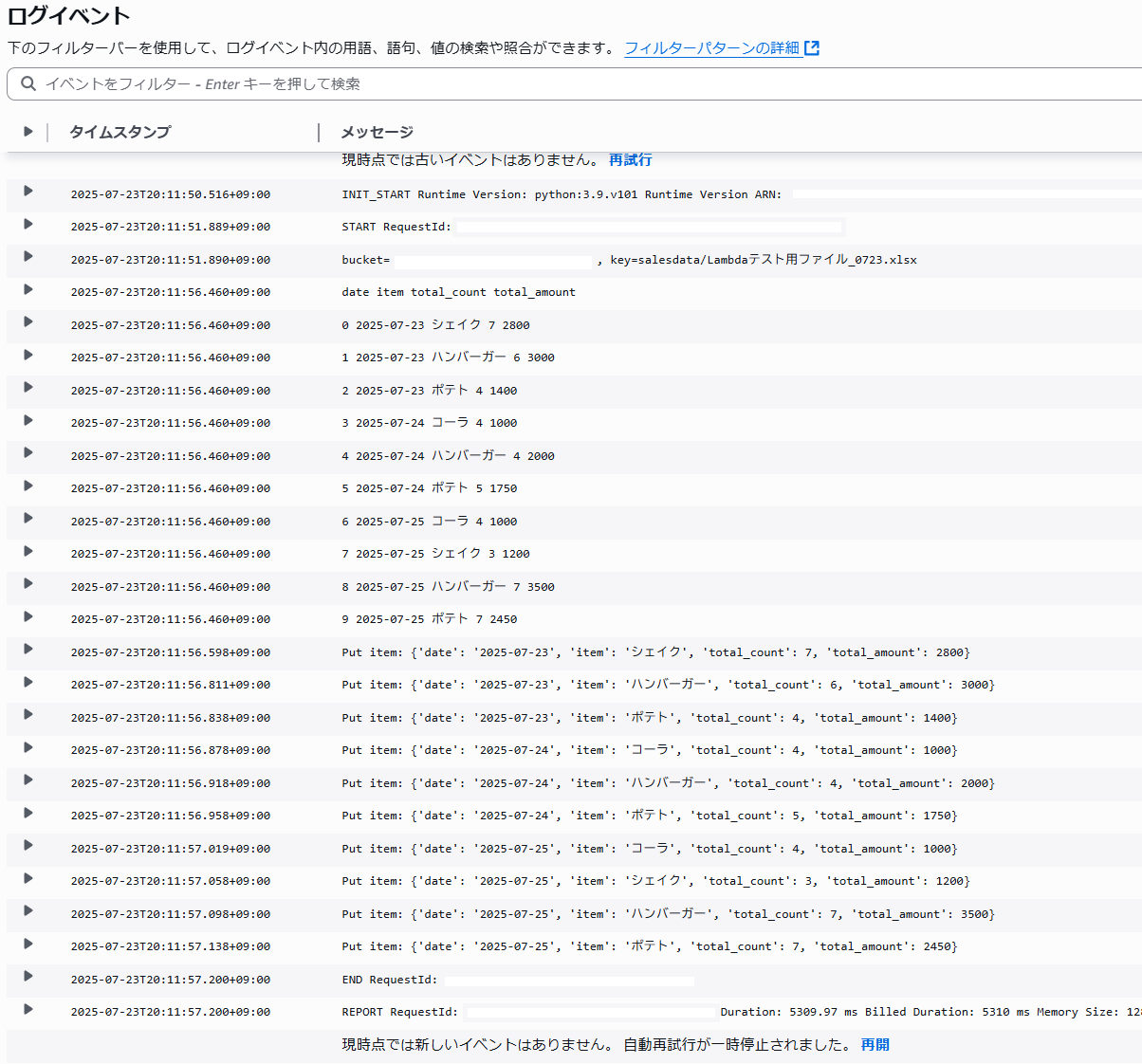
- Lambdaの実行ログを確認し処理が成功していることを確認します。
- DynamoDBにデータが格納されていることを確認します。
ExcelファイルをS3にアップロード。
Lambda > モニタリング > Cloudwatchログを表示からログを確認、エラー終了していないことを確認。
DynamoDBテーブルをスキャンしてデータが格納されていることを確認!
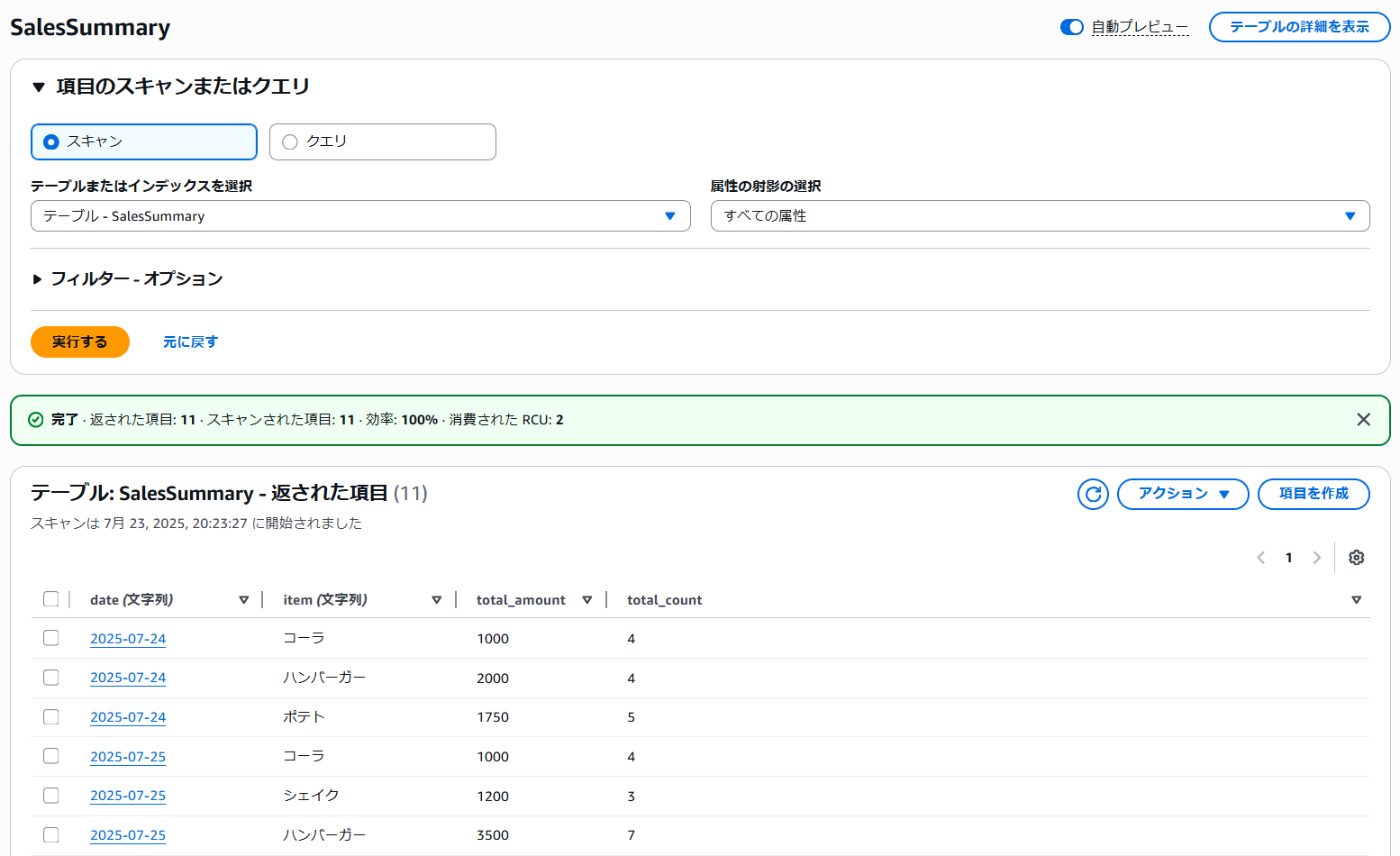 取りこめてる!やった~!
取りこめてる!やった~!
今回の学び/まとめ
今回の学びはこんな感じでした。
- LambdaでExcelファイルを処理するときは外部ライブラリとしてpandasとopenpyxlが必要
- 外部ライブラリはLambdaレイヤーにすると他の関数にも使いまわせて便利
- Lambdaのタイムアウトはデフォルト(3秒)より長くしておいたほうが良い
- ファイル名に日本語が含まれる場合、urllib.parse.unquote_plusでデコードが必要
とりあえずデータの取り込みはできたので、これから自動化など試していければと思います。今回は以上です!ありがとうございました!
この記事は私が書きました
松原 唯介
記事一覧2024年4月入社 サービスG所属
