- 公開日
- 最終更新日
【初心者】【Athena】初心者がAWS WAFログをクエリしてみました
この記事を共有する

こんにちは、サービスGの山内です。
先日業務にてAmazon Athena(以下、Athena)を使ってAWS WAF(以下、WAF)ログをクエリする機会があったため、その時の内容を記事にしてみました。
SQLコマンドについても概要レベルの理解しかなく、Athenaも「なんとなくクエリができるサービス」程度の認識でしたが、苦戦しながらもなんとかクエリを実行することができました。
この記事が、当時の私のような方にとって少しでも助けになれば幸いです。
手順
ログの準備
私の検証環境にWAFのログが無かったため、ChatGPT君にサンプルログを作成してもらいました。
これをS3バケットにアップロードしておきます。
GPT君は、ログファイルのパスは {YYYY}/{MM}/{DD}/{HH}/ といっていますが、
実際のログファイルのパスは {YYYY}/{MM}/{DD}/{HH}/{mm} のように、分単位でフォルダが作成されるはずなので注意ですね。
※これに気が付かず結構ハマりました、、、
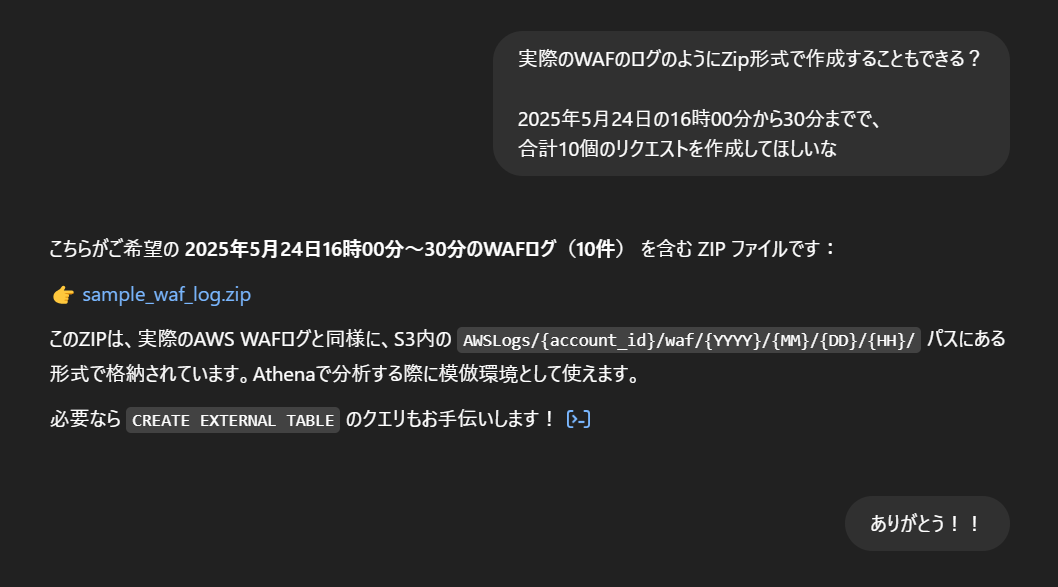
ワークグループの作成
ワークグループを分ける必要がある場合は、用途や目的に応じて分けましょう。
共通アカウントを使用している場合は、エンジニア単位などで分けると管理がしやすいと思います。
- Athenaのマネジメントコンソール画面から、ワークグループを選択し、右上のワークグループの作成をクリックします。
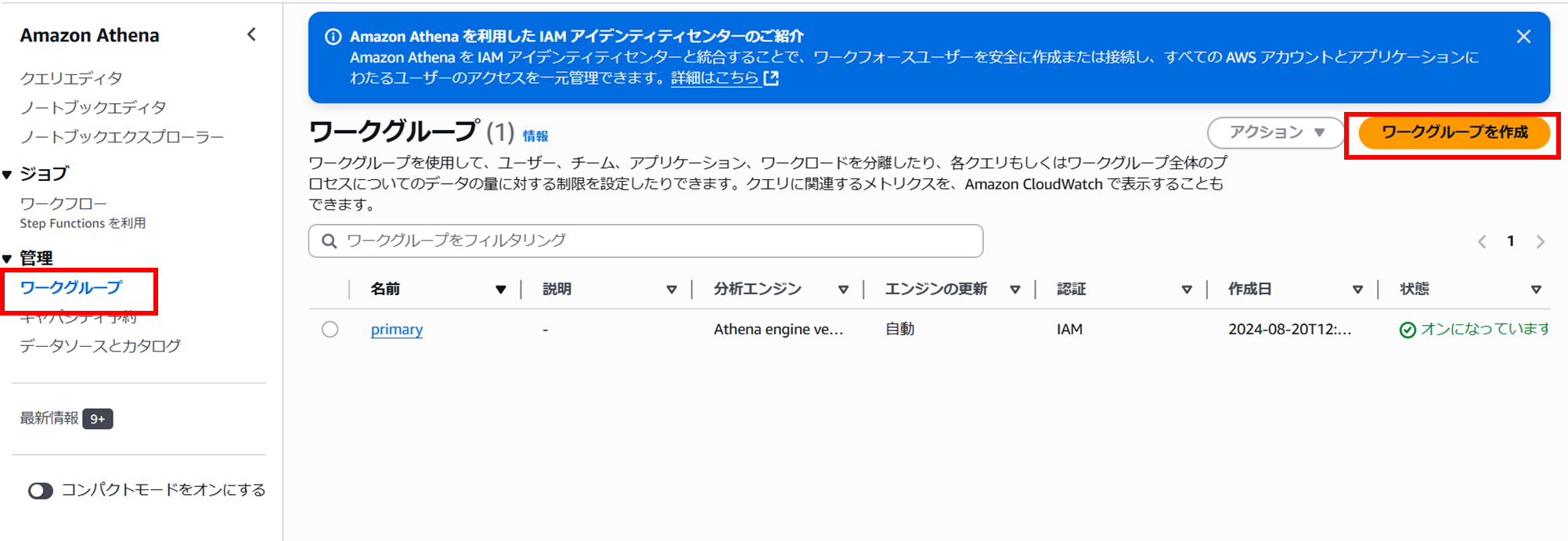
- ワークグループ名を設定し、追加の設定はせず、ワークグループの作成をクリックします。
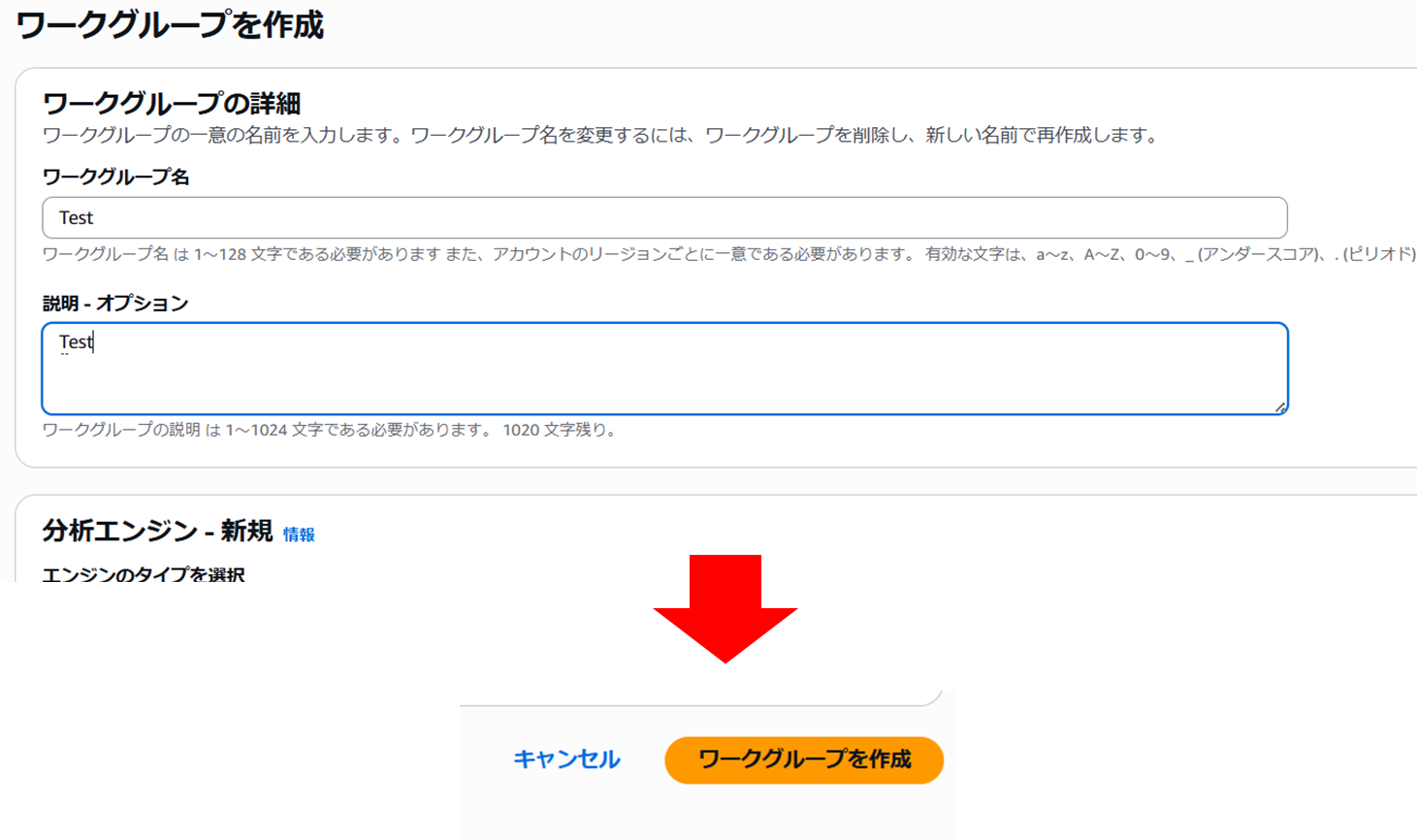
- ワークグループが完成しました。
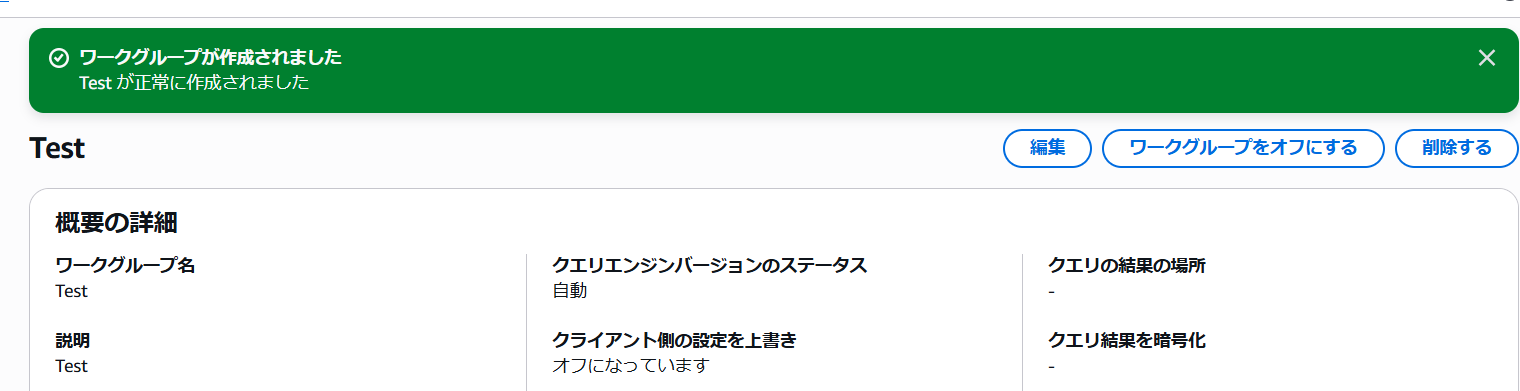
クエリ結果の保存先の指定
初めて利用する場合は、クエリ結果を保存するS3の設定が必要です。
保存先の設定がないとクエリを実行できません。
- 設定タブの管理をクリックします。
- クエリ結果保存場所に保存先バケットを記載し、保存をクリックします。
 これで保存先設定が完了しクエリが実行できるようになります。
これで保存先設定が完了しクエリが実行できるようになります。
データベース作成
テーブルが格納されるデータベースを作成します。
- 左ペインのクエリエディタを選択し、右上のワークグループを先ほど作成したワークグループに切り替えます。

- 下記コマンドをコピーし、クエリ1のウィンドに張り付け、実行をクリックします。
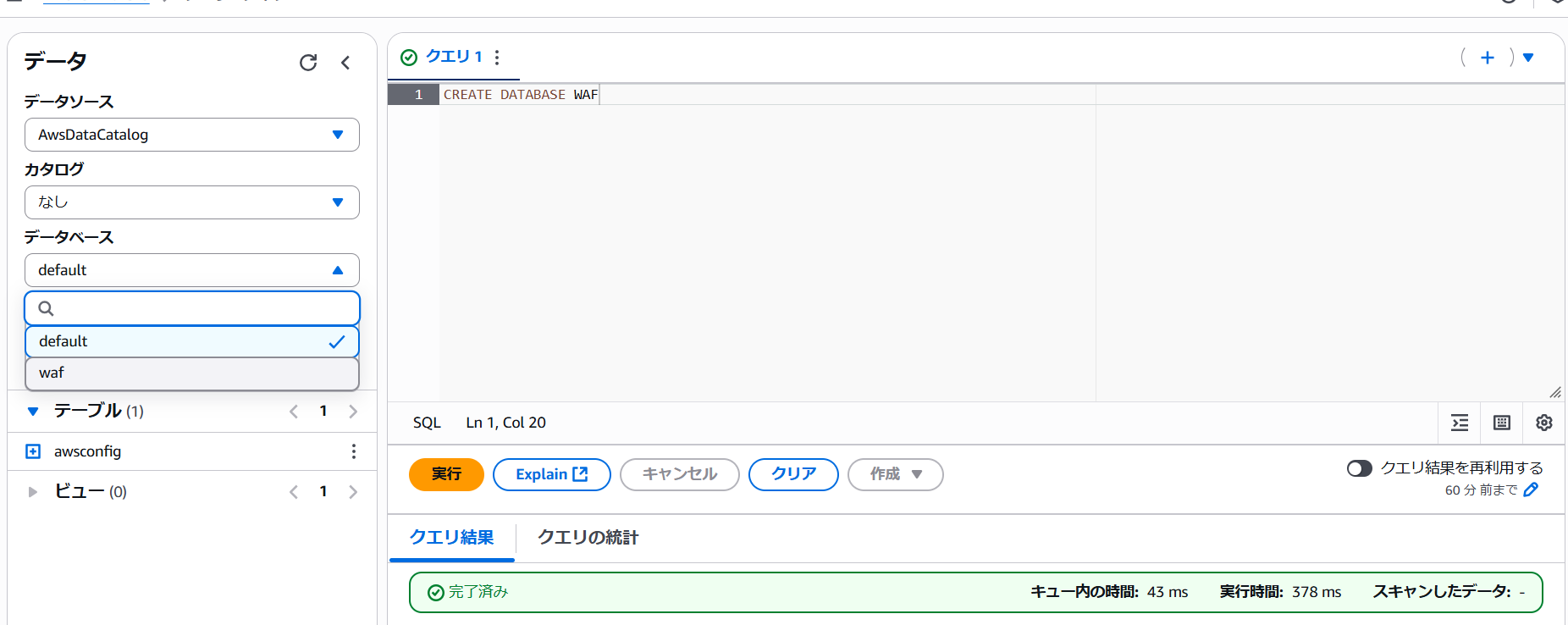
CREATE DATABASE <データベース名>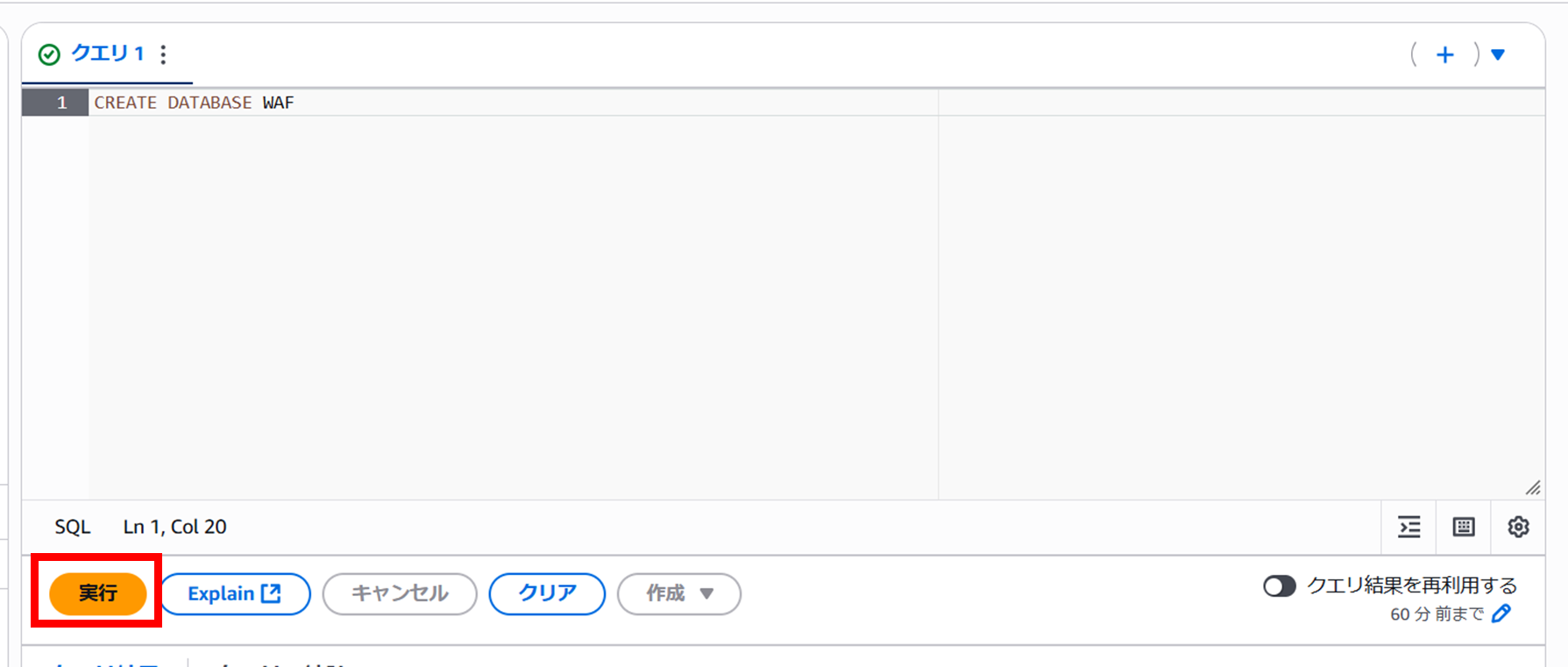 3. クエリが完了すると、左ペインのデータベース内にて作成したデータベースを選択できるようになります。
3. クエリが完了すると、左ペインのデータベース内にて作成したデータベースを選択できるようになります。
テーブル作成
テーブルを作成します。テーブルの作成コマンドはAWS公式の下記ページを参考にしています。
下記ページでは、パーティション射影という機能を使ってテーブルを作成しています。
パーティション射影を使うことで、日々増えていくWAFのログを自動でテーブルに取り込むことができるため、即座にクエリを実行できるようになります。
パーティション射影を使わない場合は、クエリを実行したいデータを手動でテーブルに取り込む必要があります。
Create a table for AWS WAF S3 logs in Athena using partition projection
- 下記コマンドをコピーし、クエリを実行します。
CREATE EXTERNAL TABLE `waf_logs_partition_projection`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array>>,
`httpsourcename` string,
`httpsourceid` string,
`rulegrouplist` array>>>,nonterminatingmatchingrules:array>>,challengeresponse:struct,captcharesponse:struct>>,excludedrules:string>>,
`ratebasedrulelist` array>,
`nonterminatingmatchingrules` array>>,challengeresponse:struct,captcharesponse:struct>>,
`requestheadersinserted` array>,
`responsecodesent` string,
`httprequest` struct>,uri:string,args:string,httpversion:string,httpmethod:string,requestid:string,fragment:string,scheme:string,host:string>,
`labels` array>,
`captcharesponse` struct,
`challengeresponse` struct,
`ja3fingerprint` string,
`ja4fingerprint` string,
`oversizefields` string,
`requestbodysize` int,
`requestbodysizeinspectedbywaf` int)
PARTITIONED BY (
`log_time` string)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://amzn-s3-demo-bucket/AWSLogs/AWS_ACCOUNT_NUMBER/WAFLogs/cloudfront/testui/'
TBLPROPERTIES (
'projection.enabled'='true',
'projection.log_time.format'='yyyy/MM/dd/HH/mm',
'projection.log_time.interval'='1',
'projection.log_time.interval.unit'='minutes',
'projection.log_time.range'='2025/01/01/00/00,NOW',
'projection.log_time.type'='date',
'storage.location.template'='s3://amzn-s3-demo-bucket/AWSLogs/AWS_ACCOUNT_NUMBER/WAFLogs/cloudfront/testui/${log_time}') waf_logs_partition_projection部分にはテーブル名を、
LOCATION とstorage.location.templateにはWAFログの保存先を記載してください。
WAFログの保存先のパスは、コマンドの通りWebACL名のフォルダまでの指定で大丈夫です。
また、 projection.log_time.rangeにて時間範囲を指定できます。
今回は2025/01/01/00/00,NOWとしているため、実際にクエリする際は適切な設定を記載してください。
成功すると左ペインにテーブルが作成されます。
テーブルをプレビュー
クエリ実行の前に、プレビュー機能を使ってどんな値が格納されているのかを確認してみます。
- 作成したテーブルの三点リーダーをクリックし、テーブルをプレビュー をクリックします。
- 下記のコマンドが実行され、最初から10番目までのデータが出力されます。
SELECT * FROM "waf"."waf_logs" limit 10; 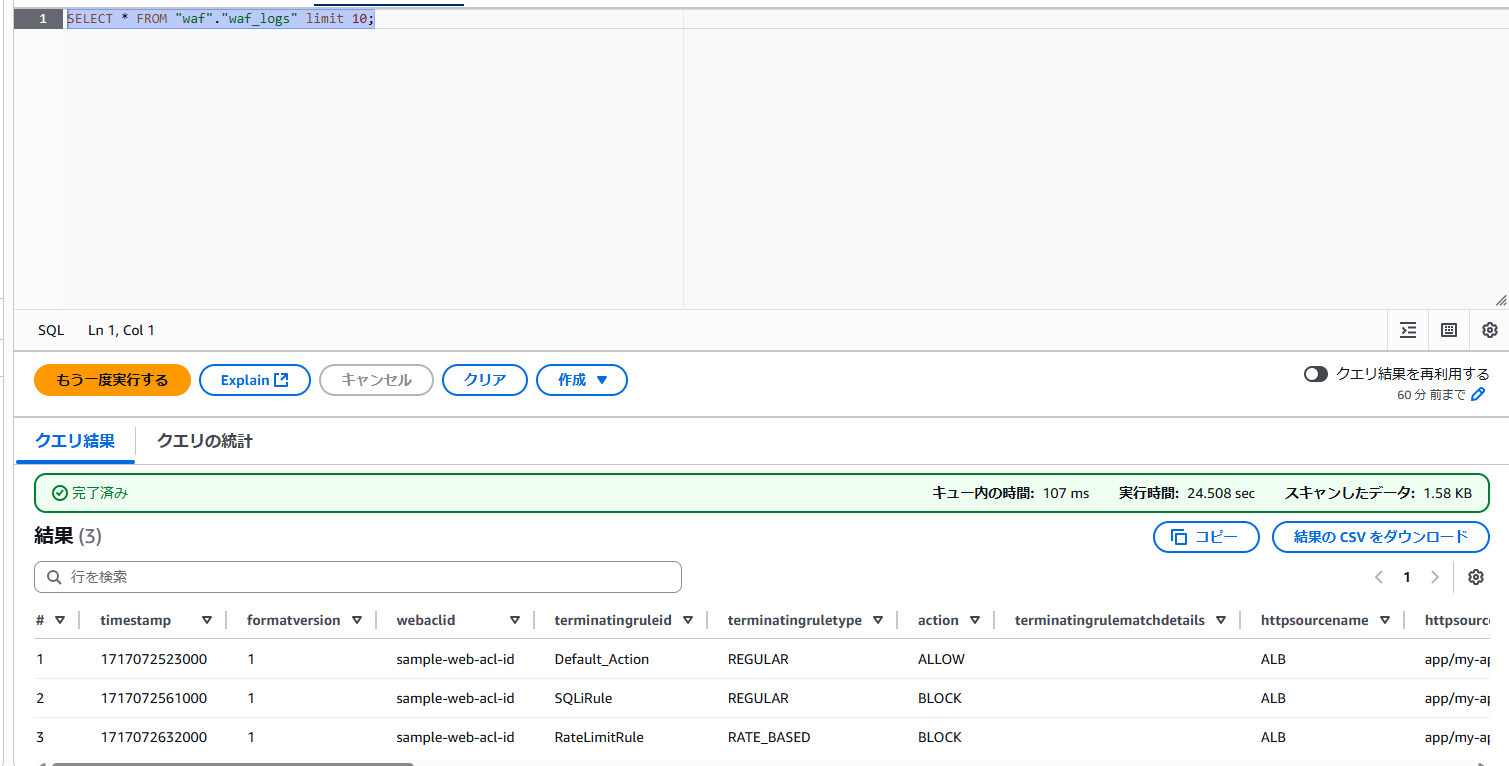
クエリの実行
私が実行したクエリをいくつかご紹介します。
先ほどのテーブルをプレビュー の結果を確認しながら、実行するクエリを作成しました。
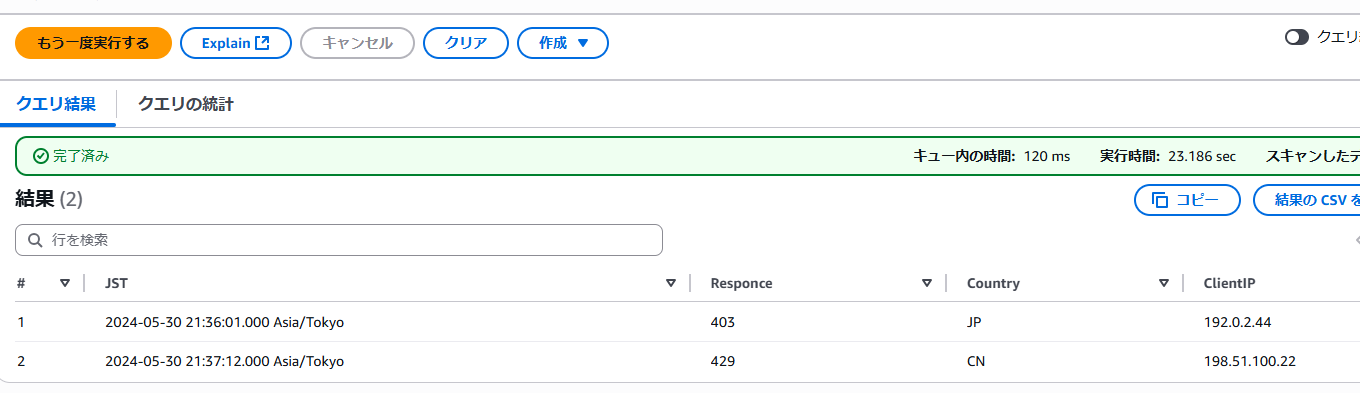
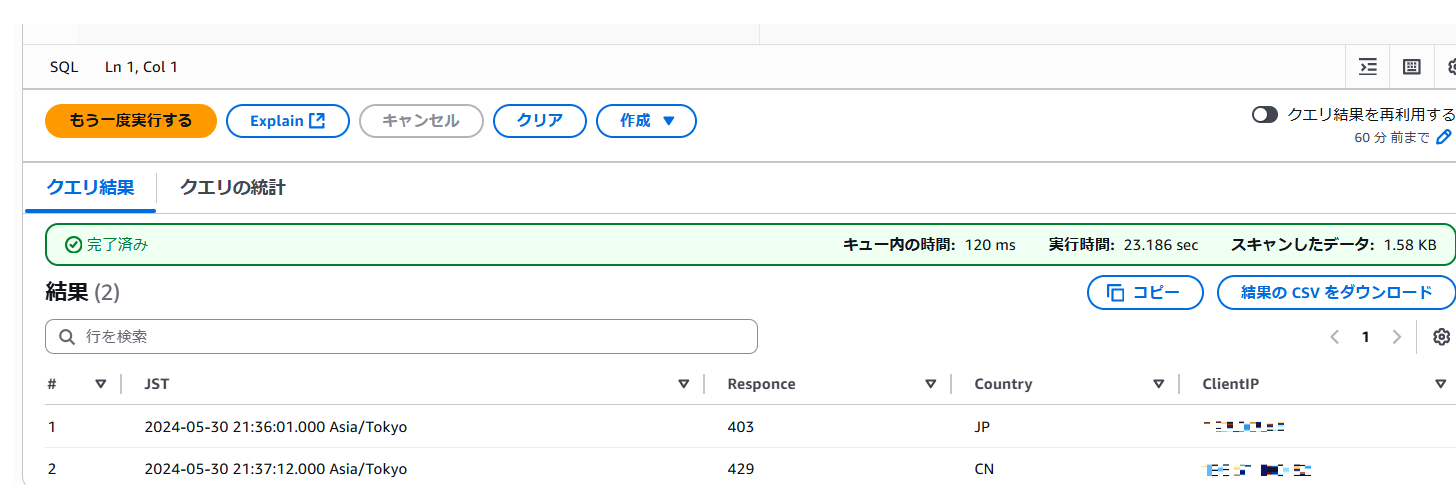
400系エラーとなっているClientIPを確認するクエリ
SELECT
from_unixtime(timestamp/1000, 'Asia/Tokyo') AS JST,
responsecodesent AS Responce,
httprequest.Country AS Country,
httprequest.clientip AS ClientIP
FROM
"waf"."waf_logs"
where
action = 'BLOCK'
timestampの値がミリ秒のUNIXタイムとなっているため、from_unixtimeを使って変換を行っています。
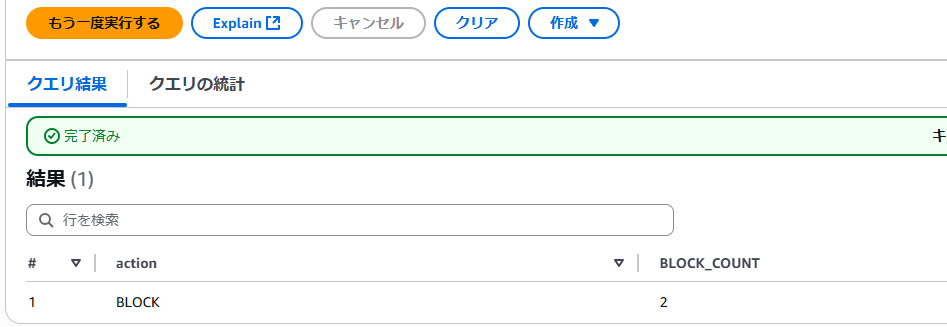
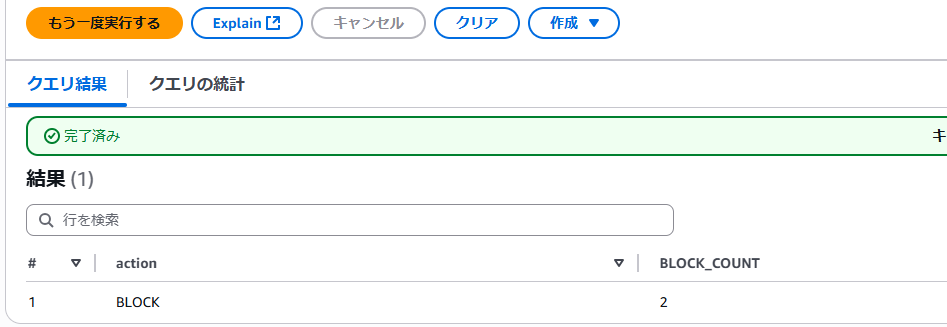
BLOCKとなっているログをカウントするクエリ
SELECT
action,
COUNT(*) AS BLOCK_COUNT
FROM
"waf"."waf_logs"
WHERE
action = 'BLOCK'
GROUP BY
action;
テーブル定義コマンドの詳細
備忘を兼ねて、テーブル定義コマンドの詳細をまとめます。
実は今回ブログを投稿する上で、一番書きたかったのがここの部分になります。
CREATE EXTERNAL TABLE
テーブル名と、ログのそれぞれのフィールドをどのような型で取り込むのかを定義しています。
必ずしもすべてのフィールドを定義する必要はないようです。
CREATE EXTERNAL TABLE `waf_logs_partition_projection`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array>>,
`httpsourcename` string,
`httpsourceid` string,
## 省略
`requestbodysizeinspectedbywaf` int) PARTITIONED BY
ここで指定したキーで、データを分割して集計しパーティション化します。
パーティション化することで、クエリの範囲を絞ることができ、効率的にクエリを実行することができます。
今回のテーブル定義コマンドでは、時間ごとに集計しています。
PARTITIONED BY (
`log_time` string)
ROW FORMAT SERDE
Athenaがどんな種類のデータを処理するのかを指定します。
今回はJSONのため、org.openx.data.jsonserde.JsonSerDeを指定しています。
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
テーブルの入力データのファイル形式を指定します。
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
テーブルの出力データのファイル形式を指定します。
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
データが保存されているS3のパスを指定します。
LOCATION
's3://amzn-s3-demo-bucket/AWSLogs/AWS_ACCOUNT_NUMBER/WAFLogs/cloudfront/testui/'
TBLPROPERTIES
テーブルのメタデータを指定します。
この項目でパーティション射影の設定を行っています。
詳細はこちらをご参照ください。
'projection.enabled'='true'
パーティション射影を有効化しています。
'projection.log_time.format'='yyyy/MM/dd/HH/mm'
日付の型を指定しています。実際のログがどのようなパスで保管されているかを確認して記載します。
'projection.log_time.interval'='1'
ログデータの間隔を指定します。
'projection.log_time.interval.unit'='minutes'
ログデータの間隔の単位を指定します。
'projection.log_time.interval'='1'と合わせることで、1分間隔を表現しています。
'projection.log_time.range'='2025/01/01/00/00,NOW'
ログデータの範囲を指定します。
'projection.log_time.type'='date'
射影の型を指定します。
'storage.location.template'='s3://amzn-s3-demo-bucket/AWSLogs/AWSACCOUNTNUMBER/WAFLogs/cloudfront/testui/${log_time}')
キーを含んだログが保管されているS3のパスを指定します。 パーティション射影の設定でlog_timeというキーを指定したため、それを含んだパスとなっています。
おわりに
記事を執筆することで、テーブル定義についての理解が深まり、良かったです。
Athenaのテーブル定義が分かると、WAFログだけではなくVPC Flow LogやCloudFrontのログのクエリもできるようになると思います。
今後はそういったログのクエリについても記事にできればと思います。
この記事は私が書きました
山内 宏紀
記事一覧CloudFormationが好きです。 使っているギターはSGです。
